在实习时候用到了local cache组件,当时在本地缓存和redis之间还是纠结过,最后选了go的freecache来作本地缓存,结合底层相关知识整理了一篇总结,之后有时间在写一篇关于Redis的介绍。
缓存
在将local cache组件之前,我们先来讲点关于缓存的事情。一次性读取一块内存的数据存放到 cache 中, 这个块称为 cache line , cache line 的大小是固定的,通常是 2 的 N 次方(16 ~ 256 byte)
缓存结构
假设内存容量为M,内存地址为m位:那么寻址范围为000…00~FFF…F(m位) 我们可以把内存地址分为以下三个区间:
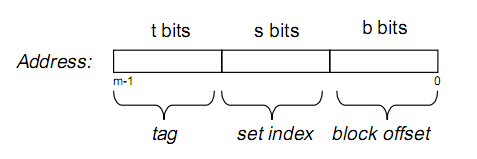
那么tag, set index, block offset三个区间有什么用呢?再来看Cache的逻辑结构:
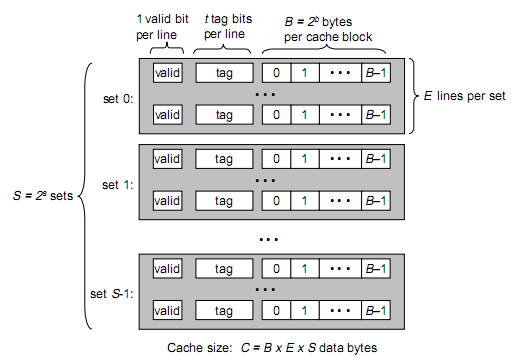
将两图做对比,可以得出:B = 2^b, S = 2^s
cache参数
一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中有B个存储单元(现代处理器中,这个存储单元一般是以字节(8 bits)为单位的,也是最小的寻址单元)因此在一个内存地址中,中间的s位决定了该单元被映射到哪一组,而最低的b位决定了该单元在cacheline中的偏移量。
valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,显然是无效的)
tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元。
当tag和valid校验成功时,称cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败时,就说明要访问的内存单元(也可能是连续的一些单元,如int占4个字节,double占8个字节)并不在cache中,这时就需要去内存中取了,这就是cache不命中的情况(cache miss)不命中发生时,系统会从内存中取得该单元,将其装入cache中,同时也放入CPU寄存器中,等待下一步处理。
从内存中取单元到cache时,会一次取一个cacheline大小的内存区域到cache中并存进相应的cacheline中。
例如:我们要取地址 (t, s, b) 内存单元,发生了cache miss,那么系统会取 (t, s, 00…000) 到 (t, s, FF…FFF)的内存单元,将其放入相应的cacheline中。
下面看看cache的映射机制:
当E=1时, 每组只有一个cacheline。那么相隔2^(s+b)个单元的2个内存单元,会被映射到同一个cacheline中(两个单元的索引位和偏移位相同)
当1<E<C/B时,每组有E个cacheline,不同的地址,只要中间s位相同,那么就会被映射到同一组中,同一组中被映射到哪个cacheline中是依赖于替换算法的。
当E=C/B,此时S=1,每个内存单元都能映射到任意的cacheline。带有这样cache的处理器几乎没有,因为这种映射机制需要昂贵复杂的硬件来支持。
不管哪种映射,只要发生了cache miss,那么必定会有一个cacheline大小的内存区域,被取到cache中相应的cacheline。
多级缓存
由于CPU的运算速度超越了1级缓存的数据I\O能力,CPU厂商又引入了多级的缓存结构:
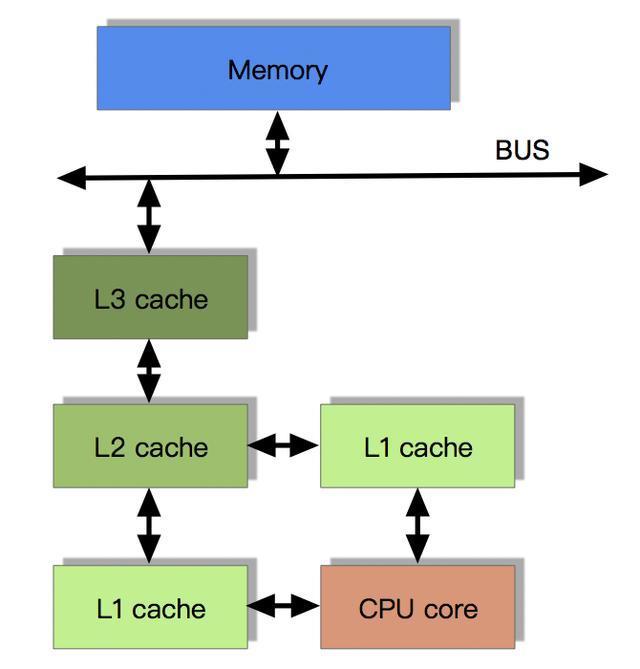
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。
当 CPU 写数据的时候,需要保证该数据在多个 CPU cache 之间的一致性。在写之前必须先让其他 CPU cache 中的该数据失效,之后才可以安全的写数据。如果这个数据已经存在于要执行写指令的 CPU cache 中,但为 read only 的,这个过程被称为 “write miss” ,一旦其他 CPU cache 中的该数据都失效后,该 CPU 可以不断的写或读其 cache 中的数据。如果另外某一个 CPU 尝试访问该数据,会形成一次 cache miss ,这时称为 “communication miss” ,因为这通常是多个 CPU 之间使用缓存通信造成的。
缓存一致性
MESI协议用于保证多个CPU cache之间缓存共享数据的一致性。它定义了CacheLine的四种数据状态,而CPU对cache的四种操作可能会产生不一致的状态。因此缓存控制器监听到本地操作与远程操作的时候需要对地址一致的CacheLine状态做出一定的修改,从而保证数据在多个cache之间流转的一致性。
协议在每一个 cache line 中维护一个两位的状态 “tag” ,这个 “tag” 在 cache line 的物理地址或者数据后。
modified 状态的 cache line 是由于相应的 CPU 进行了写操作,同时也表示该数据不会存在于其他 CPU 的 cache 中。也就说明这个最新的数据目前是被执行写操作的 CPU cache line 独占的。因为如此当前 cache 需要对该数据负责,比如将该数据传递给其他 CPU cache ,或者是将该数据写回到 memory 中。而这些操作都需要在 reuse cache line (置换)之前完成。
exclusive 状态和 modified 状态类似,区别是 CPU 还没有修改 cache line 中的数据。在 exclusive 状态下 CPU 可以不通知其他 CPU 而直接 cache line 进行操作。也就是说 exclusive 状态是该 CPU 对这个数据的独占。此时由于 memory 中和 cache line 中的数据都是最新的,所以不需要对 exclusive 状态的 cache line 执行写回 memory 的操作就可以直接 reuse。
shared 状态的 cache line ,其数据可能在一个或者是多个 CPU cache 中,此时 CPU 不能直接修改 cache line 中的数据,而是需要先通知其他 CPU cache 。和 exclusive 一样, shared 状态的 cache line 对应的 memory 中的数据也是最新的,因此也可以直接 reuse cache line。
invalid 状态时 cache line 是空的。当新的数据要进入 cache 的时候优先选择 invalid 的 cache line ,之所以如此是因为如果选中其他状态的 cache line 会涉及到 cache line 中数据的置换 , 而之后如果这个被替换的数据被访问到会造成 cache miss ,这样造成很大的开销。
状态变迁
modify
当前CPU中数据的状态是modify,表示当前CPU中拥有最新数据,虽然主存中的数据和当前CPU中的数据不一致,但是以当前CPU中的数据为准;
- LR:此时如果发生local read,即当前CPU读数据,直接从cache中获取数据,拥有最新数据,因此状态不变;
- LW:直接修改本地cache数据,修改后也是当前CPU拥有最新数据,因此状态不变;
- RR:因为本地内存中有最新数据,当本地cache控制器监听到总线上有RR发生的时,必然是其他CPU发生了读主存的操作,此时为了保证一致性,当前CPU应该将数据写回主存,而随后的RR将会使得其他CPU和当前CPU拥有共同的数据,因此状态修改为S;
- RW:同RR,当cache控制器监听到总线发生RW,当前CPU会将数据写回主存,因为随后的RW将会导致主存的数据修改,因此状态修改成I;
exclusive
当前CPU中的数据状态是exclusive,表示当前CPU独占数据(其他CPU没有数据),并且和主存的数据一致;
- LR:从本地cache中直接获取数据,状态不变;
- LW:修改本地cache中的数据,状态修改成M(因为其他CPU中并没有该数据,因此不存在共享问题,不需要通知其他CPU修改cache line的状态为I);
- RR:本地cache中有最新数据,当cache控制器监听到总线上发生RR的时候,必然是其他CPU发生了读取主存的操作,而RR操作不会导致数据修改,因此两个CPU中的数据和主存中的数据一致,此时cache line状态修改为S;
- RW:同RR,当cache控制器监听到总线发生RW,发生其他CPU将最新数据写回到主存,此时为了保证缓存一致性,当前CPU的数据状态修改为I;
shared
当前CPU中的数据状态是shared,表示当前CPU和其他CPU共享数据,且数据在多个CPU之间一致、多个CPU之间的数据和主存一致;
- LR:直接从cache中读取数据,状态不变;
- LW:发生本地写,并不会将数据立即写回主存,而是在稍后的一个时间再写回主存,因此为了保证缓存一致性,当前CPU的cache line状态修改为M,并通知其他拥有该数据的CPU该数据失效,其他CPU将cache line状态修改为I;
- RR:状态不变,因为多个CPU中的数据和主存一致;
- RW:当监听到总线发生了RW,意味着其他CPU发生了写主存操作,此时本地cache中的数据既不是最新数据,和主存也不再一致,因此当前CPU的cache line状态修改为I;
invalid
当前CPU中的数据状态是invalid,表示当前CPU中是脏数据,不可用,其他CPU可能有数据、也可能没有数据;
LR:因为当前CPU的cache line数据不可用,因此会发生读内存,此时的情形如下。
- 如果其他CPU中无数据则状态修改为E;
- 如果其他CPU中有数据且状态为S或E则状态修改为S;
- 如果其他CPU中有数据且状态为M,那么其他CPU首先发生RW将M状态的数据写回主存并修改状态为S,随后当前CPU读取主存数据,也将状态修改为S;
LW:因为当前CPU的cache line数据无效,因此发生LW会直接操作本地cache,此时的情形如下。
- 如果其他CPU中无数据,则将本地cache line的状态修改为M;
- 如果其他CPU中有数据且状态为S或E,则修改本地cache,通知其他CPU将数据修改为I,当前CPU中的cache line状态修改为M;
- 如果其他CPU中有数据且状态为M,则其他CPU首先将数据写回主存,并将状态修改为I,当前CPU中的cache line转台修改为M;
RR:监听到总线发生RR操作,表示有其他CPU读取内存,和本地cache无关,状态不变;
- RW:监听到总线发生RW操作,表示有其他CPU写主存,和本地cache无关,状态不变;
store buffer
这里算是一些小的补充,为了加速MESI协议中的一些操作,硬件上引入store buffer和invalid queue的原因。
(也是对之前那篇PRWLOCK博文的补充,关于cache,store buffer,memory barry的关系)
一般对 MESI 的简单实现都是没有实际价值,这是因为发生写操作往往会带来很长时间的等候:首先需要写的 CPU 需要让别的 CPU 将状态转换到 invalid,收到 response 以后才能进行实际的写,为此硬件上使用了 store buffer,store buffer 的作用是让 CPU 需要写的时候仅仅将其操作交给 store buffer,然后继续执行下去,store buffer 在某个时刻就会完成一系列的同步行为;很明显这个简单的东西会违背 self consistency,因为如果某个 CPU 试图写其他 CPU 占有的内存,消息交给 store buffer 后,CPU 继续执行后面的指令,而如果后面的指令依赖于这个被写入的内存(尚未被更新,这个时候读取的值是错误的)就会产生问题,所以实际实现 store buffer 可能会增加 snoop 特性,即 CPU 读取数据时会从 store buffer 和 cache 两处读。
即便增加了 snoop,store buffer 仍然会违背 global memory ordering,导致的解决方案是 memory barrier:我们知道程序员书写两个写操作的时候,隐含的假定是如果能观察到后一个写的结果,那么前一个写的结果势必也会发生,这是一个非常符合人直觉的行为,但是由于 store buffer 的存在,这个结论可能并不正确:这是因为如果观察线程位于另一个 core,首先读取后一个写(该地址并不在 cache 内)需要向写入线程所在 core 要对应地址的值,由于该 core 从 store buffer 返回了新值的时候这个 buffer 里面的写操作可能尚未发生,所以观察线程在获取了后一个写的最新结果时,前一个写的结果依然无法观察到,这违背了 sequential consistency 的假定,往往程序员更倾向于这个 consistency model 下的 reasoning。
硬件 level 上很难揣度软件上这种前后依赖关系,因此往往无法通过某种手段自动的避免这种问题,只有通过软件的手段表示(对应也需要硬件提供某种指令来支持这种语义),这个就是 memory barrier,从硬件上来看这个 barrier 就是 CPU flush 其 store buffer 的指令,那么一种做法就是提供给程序员对应的指令(封装到函数里面)要求在合适的时候插入表达这种关系,另一种做法就是通过某种标识让编译器翻译的时候自动的插入这个指令。
往往 store buffer 都很小,针对连续写操作力不从心,类似的情况也发生在碰到 memory barrier 之后。开始写之前首先需要 invalidate 其他 cache 里面的数据,为了加速这个过程硬件设计者又加入了 invalidate queue,这个 queue 将 incoming 的 invalidate 消息存放,立即返回对应的 response 这样以便发起者能尽快做后面的事情,而这个 CPU 可以通过 invalidate queue 后续处理这些内存。invalidate queue 的存在会使得我们有更多的地方需要 memory barrier(理由与 store buffer 类似)实际 memory barrier 又有一些细分,如 read/write 的,软件上会通过 smb_mb/rmb/wmb 等表示,对应的硬件指令不同平台下各不相同。实际实现的时候由于某些指令集之间的关系使得 memory barrier 的实现不可能做到最优,很多常见的平台都使用了简单粗暴的 bus 锁(x86、amd64、armv7),这也就是 Sutter talk 里面认为硬件平台往往提供了一些“过度”的指令的原因,最终软件需要的 sequential consistency 尽管得以实现,但是产生了一些不必要的代价。
local cache
回顾了一下底层的知识,我们接下来谈谈本地缓存组件。首先是我当时为什么不用redis而用了local cache。
我实际需要的场景是:我上个服务会发大量数据给这个服务,我需要将拥有相同tag的数据识别为一类,生成一个unique key,即一个tag对应一个key的一对一关系。每条数据落库时都会写下这个key。那我为什么不用redis来维护这个 tag->key 的映射关系呢?因为公司没资源了,当时部门有一个通用的redis资源,但我这个项目完全是脱离开的离线项目,和那些个在线项目抢资源总是不太放心。其次是会需要缓存一些重复的rpc请求,综合来说我更倾向于用local cache来做。
但是local cache就有个问题,多个实例间的cache是不共享的,因此我需要将同一个tag的数据收敛到同一个实例上,来保证cache映射对的正确性。这点就交由消息队列的partition key来做,设置partition key = {tag},然后某RMQ保证了相同partition key的数据会hash发送到同一实例的同一协程(worker)下,完美地解决了该问题。在确定好了 RMQ + local cache 的技术方案后就是 cache 组件的选取了。
首先抽象出我需要的cache特性,一个tag下的最后一条数据处理完前,该tag下的第一条数据不能被逐出cache。
但这样的一条特性太过于抽象不宜满足,但如果我们可以保证数据满足相同tag的数据彼此相邻的话,在LRU策略下只需要一块很小的cache就可以满足需要。而上游处理数据时确实是按tag顺序处理的,只需要发送给RMQ时采用有序消息即可。最后基于该特性,我选择了go下的freecache来完成需求。
freecache具有以下优势:
- 能存储数亿条记录(entry) 。
- 零GC开销。
- 高并发线程安全访问。
- 纯Golang代码实现。
- 支持记录(entry)过期。
- 接近LRU的替换算法。
- 严格限制内存的使用。
- 提供一个测试用的服务器,支持一些基本 Redis 命令。
- 支持迭代器。

