记录下休学期间学习Go语言入门的一些想法、笔记和踩过的一些坑。
希望之后这个Go系列还会继续完善下去不被弃坑(小声)
安装下载
因为一些奇怪的原因我分别在Windows和Linux子系统上安装了Go。
Windows
下载地址 笔者现安装的版本是go version go1.13.4 windows/amd64
安装完成后默认会在环境变量 Path 后添加 Go 安装目录下的 bin 目录 C:\Go\bin\,并添加环境变量 GOROOT,值为 Go 安装根目录 C:\Go\因为笔者电脑内存不够就放在了D盘,于是修改一通环境变量,最主要就是GOROOT目录下存在go.exe以及你的代码放置区域要存在GOPATH里(GOPATH在go提出GO MOD之后就没那么重要了)。
Linux
强烈建议不要直接apt install而是去官网下载最新的版本手动安装
因为之前C++课程使用的VSCode接WSL确实用得舒服一点,就直接在WSL环境下ubuntu使用Go
第一次apt直接安装sudo apt install golang-go版本为go version go1.10.4 linux/amd64然后笔者觉得还是统一下会比较好一点(强迫症)于是去官网下了Linux的1.13版本解压在本地安装,然后因为卑微的C盘,于是把go文件夹放在了D盘,由于之Windows版本的Go放在D盘就给Linux版本文件夹重命名了一下,修改PATH:export GOPATH=/mnt/e/Program/Goexport GOROOT=/mnt/d/Go_linuxexport PATH=$PATH:$GOROOT/bin:$GOPATH/binsource /etc/profile
检查
至此理论上就能跑了,不放心可以用go version检查版本go env检查环境变量。
基础结构
用hello world信仰开头:1
2
3
4
5package main
import "fmt"
func main() {
fmt.Printf("Hello, world 你好,世界 καλημ ́ρα κóσμ こんにちはせかい\n")
}
package <pkgName>表明当前文件属于哪个包,包名main表明它是一个可独立运行的包,编译后会产生可执行文件。除了main包之外,其它的包最后都会生成*.a文件(包文件)并放置在$GOPATH/pkg/$GOOS_$GOARCH中。
每个可独立运行的Go程序,必定包含一个package main其中必含一个无参无return的入口函数main。
Go使用UTF-8字符串和标识符。
变量
使用var关键字是Go最基本的定义变量方式,Go把变量类型放在变量名后面:
1 | //初始化“variableName”的变量为“value”值,类型是“type” |
_是个特殊的变量名,任何赋予它的值都会被丢弃。eg.我们将值35赋予b,并同时丢弃34:
1 | _, b := 34, 35 |
Go对于已声明但未使用的变量会在编译阶段报错,eg.声明了i但未使用。
1 | package main |
常量
在Go程序中,常量可定义为数值、布尔值或字符串等类型。
1 | const constantName = value |
Go 常量和一般程序语言不同的是,可以指定相当多的小数位数(例如200位), 若指定給float32自动缩短为32bit,指定给float64自动缩短为64bit,详情参考链接
基础类型
Boolean
1 | //在Go中,布尔值的类型为bool,值是true或false,默认为false。 |
数值类型
Go同时支持int和uint,两种类型长度相同,但具体长度取决于编译器的实现。
Go里面也有直接定义好位数的类型:int8, int16, int32(rune), int64和uint8(byte), uint16, uint32, uint64。
不同类型的变量之间不允许互相赋值或操作!
浮点数的类型有float32和float64两种(没有float类型),默认是float64。
复数默认类型是complex128(64位实数+64位虚数)也有complex64(32位实数+32位虚数)
复数的形式为RE + IMi,其中RE是实数部分,IM是虚数部分,而最后的i是虚数单位。
字符串
1 | //Go中的字符串都是采用UTF-8字符集编码 |
在Go中字符串不能当初char数组修改,例如下面的代码编译时会报错:cannot assign to s[0]
1 | var s string = "hello" |
真的需要修改,要将字符串 s 转换为 []byte 类型,修改后再转回 string 类型:
1 | s := "hello" |
Go中可以使用+操作符来连接两个字符串
所以字符串虽不能更改,但可进行切片操作,故修改字符串也可写为:
1 | s := "hello" |
如果要声明一个多行的字符串怎么办?可以通过` 来声明:
1 | m := `hello |
` 括起的字符串为Raw字符串,即字符串在代码中的形式就是打印时的形式,它没有字符转义,换行也将原样输出。例如本例中会输出:
1 | hello |
ERROR
Go内置有一个error类型,专门用来处理错误信息,Go的package里面还专门有一个包errors来处理错误:
1 | err := errors.New("emit macho dwarf: elf header corrupted") |
分组声明
1 | import( |
代码规范
- 大写字母开头的变量是可导出的,也就是其它包可以读取的,是公有变量;
- 小写字母开头的就是不可导出的,是私有变量。
- 大写字母开头的函数相当于
class中的带public关键词的公有函数; - 小写字母开头的函数相当于
private关键词的私有函数。
内建类型
array
1 | var arr [10]int // 声明了一个int类型的数组 |
数组间的赋值是值的赋值,即当把一个数组作为参数传入函数的时候,传入的其实是该数组的副本,而不是它的指针。如果要使用指针,那么就需要用到后面介绍的slice类型了。
1 | a := [3]int{1, 2, 3} // 简短声明了一个长度为3的int数组 |
1 | // 声明了一个二维数组,该数组以两个数组作为元素,其中每个数组中又有4个int类型的元素 |
slice
初始定义数组时并不知道数组长度,在Go里面这种数据结构叫slice。
slice并不是真正意义上的动态数组,而是一个引用类型。slice总是指向一个底层array。
1 | var fslice []int |
1 | // 声明一个含有10个元素元素类型为byte的数组 |
array方括号内写明数组长度或使用...自动计算长度,声明slice时,方括号内没有任何字符。
- slice的默认开始位置是0,
ar[:n]等价于ar[0:n] - slice的默认结束位置是数组长度,
ar[n:]等价于ar[n:len(ar)] - 如果从一个数组里面直接获取slice,可以这样
ar[:]等价于ar[0:len(ar)]
slice是引用类型,所以当引用改变其中元素的值时,其它的所有引用都会改变该值。
slice内置函数:
len获取slice的长度cap获取slice的最大容量append向slice里追加一或多个元素,然后返回一个和修改后slice一样类型的slicecopy函数copy从源slice的src中复制元素到目标dst,并且返回复制的元素的个数
但当slice中没有剩余空间(即(cap-len) == 0)时,此时将动态分配新的数组空间。返回的slice数组指针将指向这个空间,而原数组的内容将保持不变;其它引用此数组的slice则不受影响。
1 | var array [10]int |
map
map也就是Python中字典的概念
1 | // 声明一个key是字符串,值为int的字典,这种方式的声明需要在使用之前使用make初始化 |
使用map过程中需要注意的几点:
- map无序,每次打印出的map会不一样,它不能通过index获取,而必须通过key获取
- map长度不固定,和slice一样是引用类型,如果两个map同时指向一个底层,一个改变,另一个也相应改变
- 内置的
len函数同样适用于map,返回map拥有的key的数量 - map的值很方便修改,通过
numbers["one"]=11可以把key为one的字典值改为11 - map和其他基本型别不同,它不是thread-safe,在多个go-routine存取时,必须使用mutex lock机制
map的初始化可以通过key:val的方式初始化值,同时map内置有判断是否存在key的方式
1 | rating := map[string]float32{"C":5, "Go":4.5, "Python":4.5, "C++":2 } |
make、new操作(TODO)
内建函数new和make是两个用于内存分配的原语,简单说new只分配内存,make用于slice,map,和channel的初始化。在Go语言中,如果一个局部变量在函数返回后仍然被使用,这个变量会从heap,而不是stack中分配内存。内建函数make(T, args)与new(T)的用途不一样。它只用来创建slice,map和channel,并且返回一个初始化的(而不是置零),类型为T的值(而不是*T)。之所以有所不同,是因为这三个类型的背后引用了使用前必须初始化的数据结构。例如,slice是一个三元描述符,包含一个指向数据(在数组中)的指针,长度,以及容量,在这些项被初始化之前,slice都是nil的。对于slice,map和channel,make初始化这些内部数据结构,并准备好可用的值。记住make只用于map,slice和channel,并且不返回指针。要获得一个显式的指针,使用new进行分配,或者显式地使用一个变量的地址。
流程控制
if
Go里面if条件判断语句中不需要括号,如下代码所示
1 | if x > 10 { |
if语句里允许声明一个变量,变量作用域只能在该条件逻辑块内,有点类似python的for i in range(100):
1 | // 计算获取值x,然后根据x返回的大小,判断是否大于10。 |
for
1 | package main |
有时我们可以省略一点
1 | sum := 1 |
甚至更省略一点,看起来就像个while,配合continue和break用风味更佳
1 | sum := 1 |
for配合range可以用于读取slice和map的数据(真的很像python啊)
1 | for k,v:=range map { |
Go 对于“声明而未被调用”的变量, 编译器会报错, 于是用_来丢弃不需要的返回值
1 | for _, v := range map{ |
switch
1 | i := 10 |
Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch, 但是可以在case最后加上fallthrough强制执行后面的case代码。
函数
声明
1 | func funcName(input1 type1, input2 type2) (output1 type1, output2 type2) { |
来个实例:
1 | package main |
当然,函数的声明还可以更人性化,可读性更强一点:
1 | func SumAndProduct(A, B int) (add int, Multiplied int) { |
变参
接受变参的函数是有着不定数量的参数的。为了做到这点,首先需要定义函数使其接受变参:
1 | func myfunc(arg ...int) {} |
arg ...int告诉Go这个函数接受不定数量的参数。注意,这些参数的类型全部是int。
在函数体中,变量arg是一个int的slice:
1 | for _, n := range arg { |
传值与传指针
当传参到函数里时,实际是传了这个值的一份copy,当在被调用函数中修改参数值的时候,调用函数中相应实参不会发生任何变化,因为数值变化只作用在copy上,而想直接传这个值本身就需要用到指针。
变量在内存中是存放于一定地址上的,修改变量实际是修改变量地址处的内存。只有add1函数知道x变量所在的地址,才能修改x变量的值。所以我们需要将x所在地址&x传入函数,并将函数的参数的类型由int改为*int,即改为指针类型,才能在函数中修改x变量的值。此时参数仍然是按copy传递的,只是copy的是一个指针。
1 | package main |
这样,我们就达到了修改x的目的。那么到底传指针有什么好处呢?
- 传指针使得多个函数能操作同一个对象。
- 传指针比较轻量级 (8bytes)只传内存地址,我们可以用指针传递体积大的结构体。如果用参数值传递的话, 在每次copy上就会花费相对较多的系统开销(内存和时间)。所以当传递大结构体的时候,用指针是一个明智的选择。
- Go语言中
channel,slice,map这三种类型的实现机制类似指针,所以可以直接传递,而不用取地址后传递指针。(注:若函数需改变slice的长度,则仍需要取地址传递指针)
defer
Go支持延迟(defer)语句,可以在函数中添加多个defer语句。当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回。
在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前需要关闭相应的资源,不然很容易造成资源泄露等问题。如下代码所示,我们一般写打开一个资源是这样操作的:
1 | func ReadWrite() bool { |
而使用defer则会显得优雅很多,在defer后指定的函数会在函数退出前调用。
1 | func ReadWrite() bool { |
如果有很多调用defer,那么defer是采用后进先出模式,所以如下代码会输出4 3 2 1 0
1 | for i := 0; i < 5; i++ { |
函数作为值、类型
在Go中函数也是一种变量,我们可以通过type来定义它
1 | type typeName func(input1 type1, input2 type2 [, ...]) (result1 type1 [, ...]) |
1 | package main |
函数当做值和类型在写一些通用接口的时候非常有用,程序灵活性也会大大增加。
Panic和Recover
Go没有像Java那样的异常机制,而是使用了panic和recover机制。BUT代码中应当没有,或很少有panic。
Panic
是一个内建函数,可以中断原有的控制流程,进入一个令人恐慌的流程中。当函数
F调用panic,函数F的执行被中断,但是F中的延迟函数会正常执行,然后F返回到调用它的地方。在调用的地方,F的行为就像调用了panic。这一过程继续向上,直到发生panic的goroutine中所有调用的函数返回,此时程序退出。恐慌可以直接调用panic产生。也可以由运行时错误产生,例如访问越界的数组。
Recover
是一个内建的函数,可以让进入令人恐慌的流程中的
goroutine恢复过来。recover仅在延迟函数中有效。在正常的执行过程中,调用recover会返回nil,并且没有其它任何效果。如果当前的goroutine陷入恐慌,调用recover可以捕获到panic的输入值,并且恢复正常的执行。
下面这个函数演示了如何在过程中使用panic
1 | var user = os.Getenv("USER") |
下面这个函数检查作为其参数的函数在执行时是否会产生panic:
1 | func throwsPanic(f func()) (b bool) { |
main函数和init函数
Go有两个保留的函数:init函数(能用于所有package)和main函数(只用于package main)。这两个函数在定义时不能有任何的参数和返回值。虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,都强烈建议在一个package中每个文件只写一个init函数。
Go程序会自动调用init()和main(),所以你不需要在任何地方调用这两个函数。每个package中的init函数都是可选的,但package main就必须包含一个main函数。
程序的初始化和执行都起始于main包。如果main包还导入了其它的包,那会在编译时将它们依次导入。若一个包被多个包同时导入,那它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次)。当一个包被导入时,如果该包还导入了其它的包,那会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话)依次类推。等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话)最后执行main函数。
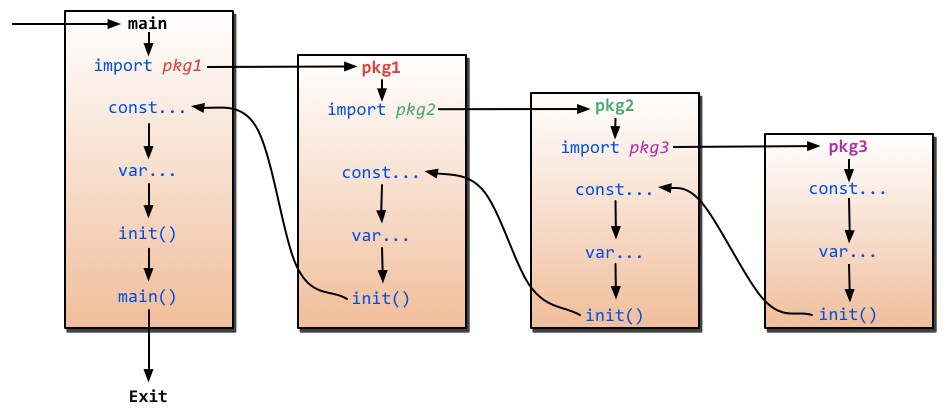
import
用import命令来导入包文件,而我们经常看到的方式参考如下:
1 | import( |
然后我们代码里面可以通过如下的方式调用
1 | fmt.Println("hello world") |
上面这个fmt是Go语言的标准库,其实是去GOROOT环境变量指定目录下去加载该模块,当然Go的import还支持用相对路径或者绝对路径来加载自己写的模块:
1 | import “./model” //当前文件同一目录的model目录,但是不建议这种方式来import |
上面展示了一些import常用的几种方式,但是还有一些特殊的import
点操作
1
2
3import(
. "fmt"
)
表示这个包导入之后,在调用这个包的函数时,可以省略前缀的包名,即调用fmt.Println("hello world")可以直接写成Println("hello world")
别名操作
1
2
3import(
f "fmt"
)
顾名思义,调用包函数时前缀变成了我们的前缀,即f.Println("hello world")
_操作
1
2
3
4import (
"database/sql"
_ "github.com/ziutek/mymysql/godrv"
)
_操作其实是引入该包,而不直接使用包里面的函数,而是调用了该包里面的init函数。
struct
1 | type person struct { |
除了上面这种P的声明使用之外,还有另外几种声明使用方式:
1.按照顺序提供初始化值
P := person{“Tom”, 25}
2.通过
field:value的方式初始化,这样可以任意顺序P := person{age:24, name:”Tom”}
3.当然也可以通过
new函数分配一个指针,此处P的类型为*personP := new(person)
struct的匿名字段
Go支持只提供类型,而不写字段名的方式,也就是匿名字段,也称为嵌入字段。
当匿名字段是一个struct的时候,那么这个struct所拥有的全部字段都被隐式地引入了当前定义的这个struct。
1 | package main |
匿名字段就是这样,能够实现字段的继承。
同时student还能访问Human这个字段作为字段名。
1 | mark.Human = Human{"Marcus", 55, 220} |
所有的内置类型和自定义类型都是可以作为匿名字段。
1 | package main |
可以看到这种类似于继承的方式,真的非常人性化了。
面向对象
函数的另一种形态,带有接收者的函数,我们称为method
method
用Rob Pike的话来说就是:
“A method is a function with an implicit first argument, called a receiver.”
method的语法如下,注意不要和function弄混哦:
1 | func (r ReceiverType) funcName(parameters) (results) |
下面我们用最开始的例子用method来实现:
1 | package main |
在使用method的时候重要注意几点
- 虽然method的名字一模一样,但是如果接收者不一样,那么method就不一样
- method里面可以访问接收者的字段
- 调用method通过
.访问,就像struct里面访问字段一样
除了结构体这一比较特殊的自定义类型外,还可以在任意自定义类型中定义任意多的method
1 | package main |
指针作为receiver
SetColor这个method,它的receiver是一个指向Box的指针,这不难理解。
Q: 那SetColor函数里应该是*b.Color=c,而不是b.Color=c才对啊,因为需要读取到指针相应的值。
A: 其实Go里面这两种方式都ok,当你用指针去访问相应的字段时(虽然指针没有任何的字段),Go知道要通过指针去获取这个值,多人性化。
Q: 那PaintItBlack里面调用SetColor不应该写成(&bl[i]).SetColor(BLACK)吗,因为SetColor的receiver是*Box,而不是Box。
A: Yep,但这两种方式都可以,因为Go知道receiver是指针,就自动帮你转了。
也就是说:
如果一个method的receiver是*T,你可以在一个T类型的实例变量V上面调用这个method,而不需要&V去调用这个method
类似的
如果一个method的receiver是T,你可以在一个T类型的变量P上面调用这个method,而不需要 P去调用这个method
method继承&重写
如果匿名字段实现了一个method,那么包含这个匿名字段的struct也能调用该method包括重写这个method。
1 | package main |
通过这些内容,我们可以设计出基本的面向对象的程序了,但是Go里面的面向对象是如此的简单,没有任何的私有、公有关键字,通过大小写来实现(大写开头的为公有,小写开头的为私有),方法也同样适用这个原则。
Interface
什么是interface
简单的说,interface是一组method签名的组合,我们通过interface来定义对象的一组行为。
interface定义了一组方法,如果某个对象实现了某个接口的所有方法,则此对象实现了此接口。
interface可以被任意的对象实现,一个对象可以实现任意多个interface。
interface值
一个interface变量可以存实现这个interface的任意类型的对象。
例如定义了一个Men interface类型的变量m,那么m可以存Human、Student或者Employee值。
因为m能够持有这三种类型的对象,那我们可以定义一个Men类型的slicex := make([]Men, 3),这个slice可以被赋予实现了Men接口的任意结构的对象。
1 | package main |
interface就是一组抽象方法的集合,必须由其他非interface类型实现,而不能自我实现。
空interface
空interface(interface{})不包含任何的method,正因为如此,所有的类型都实现了空interface。
空interface可以存储任意类型的数值,有点类似于C语言的void*类型。
1 | // 定义a为空接口 |
一个函数把interface{}作为参数,那么他可以接受任意类型的值作为参数;
如果一个函数返回interface{},那么也就可以返回任意类型的值。
interface函数参数
interface的变量可以持有任意实现该interface类型的对象,那是不是可以通过定义interface参数,让函数接受各种类型的参数。比如fmt.Println可以接受任意类型的数据,即任何实现了String方法的类型都能作为参数被fmt.Println调用。
1 | type Stringer interface { |
1 | package main |
method:String实现了fmt.Stringer这个interface,即如果需要某个类型能被fmt包以特殊的格式输出,就必须实现Stringer接口。如果没有实现这个接口,fmt将以默认的方式输出。
1 | //实现同样的功能 |
注:实现了error接口的对象(即实现了Error() string的对象),使用fmt输出时,会调用Error()方法,因此不必再定义String()方法了。
interface变量存储的类型
我们知道interface的变量里面可以存储任意类型的数值(该类型实现了interface)。那怎么反向知道这个变量里面实际保存了的是哪个类型的对象呢?目前常用的有两种方法:
Comma-ok断言
直接判断是否是该类型的变量: value, ok = element.(T),这里value就是变量的值,ok是一个bool类型,element是interface变量,T是断言的类型。
如果element里面确实存储了T类型的数值,ok返回true,否则返回false(但这样一般会引入大量if-else)
switch测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39package main
import (
"fmt"
"strconv"
)
type Element interface{}
type List [] Element
type Person struct {
name string
age int
}
//打印
func (p Person) String() string {
return "(name: " + p.name + " - age: "+strconv.Itoa(p.age)+ " years)"
}
func main() {
list := make(List, 3)
list[0] = 1 //an int
list[1] = "Hello" //a string
list[2] = Person{"Dennis", 70}
for index, element := range list{
switch value := element.(type) {
case int:
fmt.Printf("list[%d] is an int and its value is %d\n", index, value)
case string:
fmt.Printf("list[%d] is a string and its value is %s\n", index, value)
case Person:
fmt.Printf("list[%d] is a Person and its value is %s\n", index, value)
default:
fmt.Println("list[%d] is of a different type", index)
}
}
}
element.(type)语法不能在switch外的任何逻辑里面使用,如果要在switch外面判断一个类型就使用comma-ok。
嵌入interface
Go里面真正吸引人的是它内置的逻辑语法,就像我们在学习Struct时学习的匿名字段。如果一个interface1作为interface2的一个嵌入字段,那么interface2隐式的包含了interface1里面的method。
源码包container/heap里面有这样的一个定义:
1 | type Interface interface { |
另一个例子就是io包下面的 io.ReadWriter ,它包含了io包下面的Reader和Writer两个interface:
1 | // io.ReadWriter |
反射
所谓反射就是能检查程序在运行时的状态,一般用到的包是reflect包reflect包的实现原理
使用reflect一般分成三步:要去反射是一个类型的值(这些值都实现了空interface),首先需要把它转化成reflect对象(reflect.Type或者reflect.Value,根据不同的情况调用不同的函数)。
1 | t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素 |
转化为reflect对象之后我们就可以进行一些操作了,也就是将reflect对象转化成相应的值,例如
1 | tag := t.Elem().Field(0).Tag //获取定义在struct里面的标签 |
获取反射值能返回相应的类型和数值
1 | var x float64 = 3.4 |
最后,反射的字段必须是可修改的。如果下面这样写,会error
1 | var x float64 = 3.4 |
如果要修改相应的值,必须这样写
1 | var x float64 = 3.4 |

