Go日记的Web篇外传正式开张了,可喜可贺、可喜可贺!
这篇简单介绍下Go的Web基础,有计网知识或者写过前后端应该会很好上手。
Web基础
web工作方式的几个概念
Request:用户请求的信息,用来解析用户的请求信息,包括post、get、cookie、url等信息
Response:服务器需要反馈给客户端的信息
Conn:用户的每次请求链接
Handler:处理请求和生成返回信息的处理逻辑
一个简单的例子
使用go语言可以采用net/http包进行web搭建,like this:
1 | package main |
执行web.exe,此时在9090端口开始监听http链接请求
打开http://localhost:9090即可看到浏览器页面输出Hello astaxie!
我们可以对比
| map[] path / scheme [] map[] path /favicon.ico scheme [] |
map[url_long:[111 222]] path / scheme [111 222] key: url_long val: 111222 map[] path /favicon.ico scheme [] |
|---|---|
| http://localhost:9090 | http://localhost:9090/?url_long=111&url_long=222 |
http包运行机制
http包执行流程: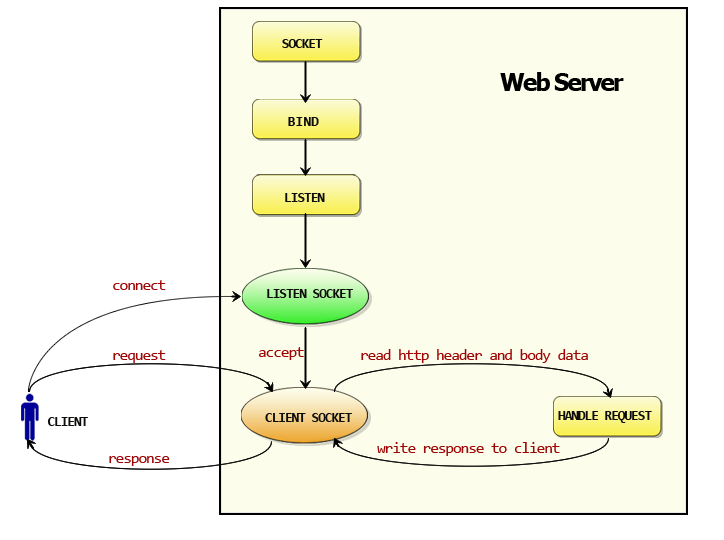
- 创建Listen Socket, 监听指定端口, 等待客户端请求。
- Listen Socket接受客户端请求, 得到Client Socket, 接下来通过Client Socket与客户端通信。
- 处理客户端请求, 首先从Client Socket读取HTTP请求的协议头, 如果是POST方法, 还可能要读取客户端提交的数据, 然后交给相应的handler处理请求, handler处理完毕准备好客户端需要的数据, 通过Client Socket写给客户端。
Go是如何让Web运行起来:如何监听端口?如何接收客户端请求?如何分配handler?
Go通过函数ListenAndServe来处理,即例子中err := http.ListenAndServe(":9090", nil)
具体如下:先初始化一个server对象,然后调用函数net.Listen("tcp", addr),即底层用TCP协议搭建了一个服务,然后监控我们设置的端口。
下面代码来自Go的http包的源码,可以看到整个的http处理过程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
var tempDelay time.Duration // how long to sleep on accept failure
for {
rw, e := l.Accept()
if e != nil {
if ne, ok := e.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
log.Printf("http: Accept error: %v; retrying in %v", e, tempDelay)
time.Sleep(tempDelay)
continue
}
return e
}
tempDelay = 0
c, err := srv.newConn(rw)
if err != nil {
continue
}
go c.serve()
}
}
监控之后如何接收客户端的请求?
上面代码执行监控端口之后,调用函数srv.Serve(net.Listener)处理接收客户端的请求信息。
这个函数里面起了一个for{},首先通过Listener接收请求,其次创建一个Conn,最后单独开了一个goroutine,把这个请求的数据当做参数扔给这个conn去服务:go c.serve()体现高并发,用户的每一次请求都是在一个新的goroutine去服务,互不影响。
如何具体分配到相应的函数来处理请求呢?
conn首先会解析request:c.readRequest(),然后获取相应的handler:handler := c.server.Handler,也就是我们刚才在调用函数err := http.ListenAndServe(":9090", nil)时候的第二个参数,传递nil即为空,那么默认获取handler = DefaultServeMux,这个变量就是一个路由器,用来匹配url跳转到其相应的handle函数,这个变量的设置,在main的第一句http.HandleFunc("/", sayhelloName)里,相当于注册了请求/的路由规则,当请求uri为”/“,路由就会转到函数sayhelloName。DefaultServeMux会调用ServeHTTP方法,这个方法内部感觉就是sayhelloName方法的callback,最后将信息写入response反馈到client。
http连接处理的具体流程可以如下显示:
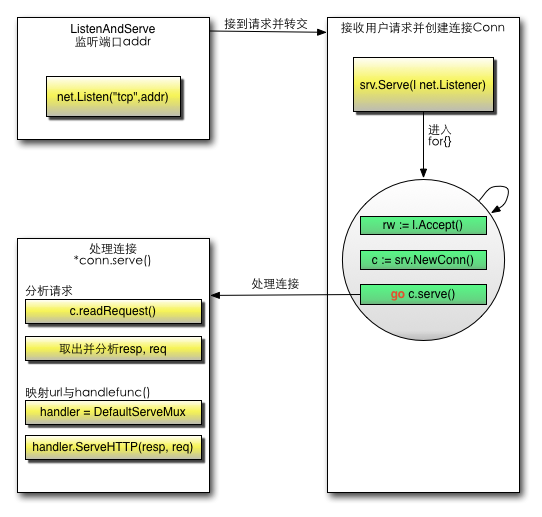
Go的http包详解
上面是过个系统性的流程(类似复习计网的感觉)接下来详谈http包:
先谈下Go的http包的两个核心功能:Conn、ServeMux
Conn的goroutine
Go为了实现高并发和高性能, 使用goroutines处理Conn的读写事件,
这样每个请求都能保持独立,相互不会阻塞,可以高效的响应网络事件。
Go在等待客户端请求里面是这样写的:
1 | c, err := srv.newConn(rw) |
client的每次请求都会创建一个Conn,这个Conn里面保存了该次请求的信息,然后再传递到对应的handler,该handler中便可以读取到相应的header信息,保证了每个请求的独立性。
ServeMux的自定义
路由器的结构
之前描述conn.server时,其实内部是调用了http包默认的路由器,通过路由器把本次请求的信息传递到了后端的处理函数。该路由器的结构如下:
1 | type ServeMux struct { |
下面看一下muxEntry的结构:
1 | type muxEntry struct { |
接着看一下Handler的定义,标准的interface,但实际使用时并不需要显示继承该接口。
1 | type Handler interface { |
在http包里定义了一个类型HandlerFunc,我们定义的函数sayhelloName就是这个HandlerFunc调用之后的结果http.HandleFunc("/", sayhelloName),这个类型默认实现了ServeHTTP接口,即我们调用了HandlerFunc(f),强制类型转换f成为HandlerFunc类型,这样f就拥有了ServeHTTP方法。不过这个使用时可以不管,但学习时候还是清楚一下比较好(小声)
1 | type HandlerFunc func(ResponseWriter, *Request) |
具体请求的分发
路由器里面存储好了相应的路由规则之后,如何实现具体请求的分发?
默认的路由器实现了ServeHTTP:
1 | func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) { |
如上所示路由器接收到请求之后,如果是*那么关闭链接,不然调用mux.Handler(r)返回对应设置路由的处理Handler,然后执行h.ServeHTTP(w, r)也就是调用对应路由的handler的ServerHTTP接口。
那么mux.Handler(r)怎么处理的呢?
1 | func (mux *ServeMux) Handler(r *Request) (h Handler, pattern string) { |
根据用户请求的URL和路由器里面存储的map去匹配的,当匹配到之后返回存储的handler,调用这个handler的ServeHTTP接口就可以执行到相应的函数了。
以上是整个路由过程,Go其实支持外部实现的路由器 ListenAndServe的第二个参数就是用以配置外部路由器的,它是一个Handler接口,即外部路由器只要实现了Handler接口就可以,我们可以在自己实现的路由器的ServeHTTP里面实现自定义路由功能。
如下代码所示,我们可以自己实现一个简易的路由器:
1 | package main |
Go代码的执行流程
通过对http包的分析之后,梳理下整个的代码执行过程:
首先调用Http.HandleFunc:
1 调用了DefaultServeMux的HandleFunc
2 调用了DefaultServeMux的Handle
3 往DefaultServeMux的map[string]muxEntry中增加对应的handler和路由规则其次调用http.ListenAndServe(“:9090”, nil):
1 实例化Server
2 调用Server的ListenAndServe()
3 调用net.Listen(“tcp”, addr)监听端口
4 启动一个for循环,在循环体中Accept请求
5 对每个请求实例化一个Conn,并且开启一个goroutine为这个请求进行服务go c.serve()
6 读取每个请求的内容w, err := c.readRequest()
7 判断handler是否为空,如果没有设置handler(这个例子就没有设置handler),handler就设置为DefaultServeMux
8 调用handler的ServeHttp
9 在这个例子中,下面就进入到DefaultServeMux.ServeHttp
10 根据request选择handler,并且进入到这个handler的ServeHTTP
mux.handler(r).ServeHTTP(w, r)
11 选择handler:
A 判断是否有路由能满足这个request(循环遍历ServeMux的muxEntry)
B 如果有路由满足,调用这个路由handler的ServeHTTP
C 如果没有路由满足,调用NotFoundHandler的ServeHTTP
表单
对于表单,写过前后端的朋友应该比较熟悉了,方便前后端数据交互。
表单是一个包含表单元素的区域。表单元素是允许用户在表单中(eg:文本域、下拉列表、单选框、复选框etc.)输入信息的元素。表单使用表单标签(\)定义。
1 | <form> |
处理表单的输入
先来看一个表单递交的例子,我们有如下的表单内容,命名成文件login.gtpl(放入当前新建项目的目录里面)
1 | <html> |
上面递交表单到服务器的/login,当用户输入信息点击登录之后,会跳转到服务器的路由login里面,我们首先要判断这个是什么方式传递过来,POST还是GET呢?
http包里面有一个很简单的方式就可以获取,在前面web例子的基础上来看看怎么处理login页面的form数据
1 | package main |
获取请求方法是通过r.Method来完成的,这是个字符串类型的变量,返回GET, POST, PUT等method信息。
login函数中我们根据r.Method来判断是显示登录界面还是处理登录逻辑。当GET方式请求时显示登录界面,其他方式请求时则处理登录逻辑,如查询数据库、验证登录信息等。
当我们在浏览器里面打开http://127.0.0.1:9090/login的时候,出现如下界面
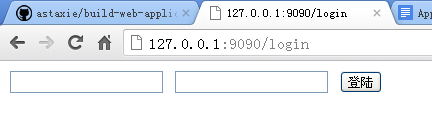
如果你看到一个空页面,可能是你写的 login.gtpl 文件中有错误,请根据控制台中的日志进行修复。
我们输入用户名和密码之后发现在服务器端是不会打印出来任何输出的,为什么呢?默认情况下,Handler里面是不会自动解析form的,必须显式的调用r.ParseForm()后,你才能对这个表单数据进行操作。我们修改一下代码,在fmt.Println("username:", r.Form["username"])之前加一行r.ParseForm(),重新编译,再次测试输入递交,现在是不是在服务器端有输出你的输入的用户名和密码了。
r.Form里面包含了所有请求的参数,比如URL中query-string、POST的数据、PUT的数据,所以当你在URL中的query-string字段和POST冲突时,会保存成一个slice,里面存储了多个值,Go官方文档中说在接下来的版本里面将会把POST、GET这些数据分离开来。
现在我们修改一下login.gtpl里面form的action值http://127.0.0.1:9090/login修改为http://127.0.0.1:9090/login?username=astaxie,再次测试,服务器的输出username是不是一个slice。服务器端的输出如下:

request.Form是一个url.Values类型,里面存储的是对应的类似key=value的信息,下面展示了可以对form数据进行的一些操作:
1 | v := url.Values{} |
Tips: Request本身也提供了FormValue()函数来获取用户提交的参数。如r.Form[“username”]也可写成r.FormValue(“username”)。调用r.FormValue时会自动调用r.ParseForm,所以不必提前调用。r.FormValue只会返回同名参数中的第一个,若参数不存在则返回空字符串。
验证表单的输入
开发Web的一个原则就是,不能信任用户输入的任何信息,所以验证和过滤用户的输入信息就变得非常重要。
~(就如某软件安全设计老师所说)~
我们平常编写Web应用主要有两方面的数据验证,一个是在页面端的js验证(目前在这方面有很多的插件库,比如ValidationJS插件),一个是在服务器端的验证,下面是如何在服务器端验证。
必填字段
通过len来获取数据的长度限定非空:
1 | if len(r.Form["username"][0])==0{ |
r.Form对不同类型的表单元素的留空有不同的处理, 对于空文本框、空文本区域以及文件上传,元素的值为空值,而如果是未选中的复选框和单选按钮,则根本不会在r.Form中产生相应条目。所以建议通过r.Form.Get()来获取值,如果字段不存在,通过该方式获取的是空值。但r.Form.Get()只能获取单个的值,如果是map的值,必须通过上面的方式来获取。
数字
如果我们是判断正整数,那么我们先转化成int类型,然后进行处理
1 | getint,err:=strconv.Atoi(r.Form.Get("age")) |
还有一种方式就是正则匹配的方式
1 | if m, _ := regexp.MatchString("^[0-9]+$", r.Form.Get("age")); !m { |
Go实现的正则是RE2,所有的字符都是UTF-8编码的。
中文
对于中文我们目前有两种方式来验证,可以使用 unicode 包提供的 func Is(rangeTab *RangeTable, r rune) bool 来验证,也可以使用正则方式来验证,这里使用最简单的正则方式,如下代码所示
1 | if m, _ := regexp.MatchString("^\\p{Han}+$", r.Form.Get("realname")); !m { |
英文
通过正则验证数据:
1 | if m, _ := regexp.MatchString("^[a-zA-Z]+$", r.Form.Get("engname")); !m { |
电子邮件地址
1 | if m, _ := regexp.MatchString(`^([\w\.\_]{2,10})@(\w{1,}).([a-z]{2,4})$`, r.Form.Get("email")); !m { |
手机号码
1 | if m, _ := regexp.MatchString(`^(1[3|4|5|8][0-9]\d{4,8})$`, r.Form.Get("mobile")); !m { |
下拉菜单
如果我们想要判断表单里面<select>元素生成的下拉菜单中是否有被选中的项目。有些时候黑客可能会伪造这个下拉菜单不存在的值发送给你,那么如何判断这个值是否是我们预设的值呢?
我们的select可能是这样的一些元素
1 | <select name="fruit"> |
那么我们可以这样来验证
1 | slice:=[]string{"apple","pear","banane"} |
单选按钮
如果我们想要判断radio按钮是否有一个被选中了,我们页面的输出可能就是一个男、女性别的选择,但是也可能一个15岁大的无聊小孩,一手拿着http协议的书,另一只手通过telnet客户端向你的程序在发送请求呢,你设定的性别男值是1,女是2,他给你发送一个3,你的程序会出现异常吗?因此我们也需要像下拉菜单的判断方式类似,判断我们获取的值是我们预设的值,而不是额外的值。
1 | <input type="radio" name="gender" value="1">男 |
那我们也可以类似下拉菜单的做法一样
1 | slice:=[]int{1,2} |
复选框
有一项选择兴趣的复选框,你想确定用户选中的和你提供给用户选择的是同一个类型的数据。
1 | <input type="checkbox" name="interest" value="football">足球 |
对于复选框我们的验证和单选有点不一样,因为接收到的数据是一个slice
1 | slice:=[]string{"football","basketball","tennis"} |
上面这个函数Slice_diff包含在大佬astaxie开源的一个库里面(操作slice和map的库)
日期和时间
Go里面提供了一个time的处理包,我们可以把用户的输入年月日转化成相应的时间,然后进行逻辑判断
1 | t := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC) |
获取time之后我们就可以进行很多时间函数的操作。具体的判断就根据自己的需求调整。
身份证号码
1 | //验证15位身份证,15位的是全部数字 |
预防XSS攻击
动态站点会受到一种名为“跨站脚本攻击”(Cross Site Scripting, 安全专家们通常将其缩写成 XSS)的威胁,而静态站点则完全不受其影响。~(还记得期末把XSS写成CSS的绝望,缩写成XSS是为了和前端CSS区分)~
攻击者通常会在有漏洞的程序中插入JavaScript、VBScript、 ActiveX或Flash以欺骗用户。一旦得手,他们可以盗取用户帐户信息,修改用户设置,盗取/污染cookie和植入恶意广告等。
对XSS最佳的防护应该结合以下两种方法:一是验证所有输入数据,有效检测攻击(这个我们前面小节已经有过介绍);另一个是对所有输出数据进行适当的处理,以防止任何已成功注入的脚本在浏览器端运行。
Go的html/template里面带有下面几个函数可以帮忙转义:
- func HTMLEscape(w io.Writer, b []byte) //把b进行转义之后写到w
- func HTMLEscapeString(s string) string //转义s之后返回结果字符串
- func HTMLEscaper(args …interface{}) string //支持多个参数一起转义,返回结果字符串
1 | fmt.Println("username:", template.HTMLEscapeString(r.Form.Get("username"))) //输出到服务器端 |
如果输入的username是<script>alert()</script>,浏览器上输出如下所示:
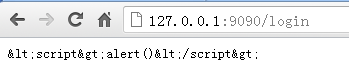
防止多次提交表单
不知道你是否曾经看到过一个论坛或者博客,在一个帖子或者文章后面出现多条重复的记录,这些大多数是因为用户重复递交了留言的表单引起的。由于种种原因,用户经常会重复递交表单。通常这只是鼠标的误操作,如双击了递交按钮,也可能是为了编辑或者再次核对填写过的信息,点击了浏览器的后退按钮,然后又再次点击了递交按钮而不是浏览器的前进按钮。当然,也可能是故意的——比如,在某项在线调查或者博彩活动中重复投票。那我们如何有效的防止用户多次递交相同的表单呢?
解决方案是在表单中添加一个带有唯一值的隐藏字段。在验证表单时,先检查带有该唯一值的表单是否已经递交过了。如果是,拒绝再次递交;如果不是,则处理表单进行逻辑处理。另外,如果是采用了Ajax模式递交表单的话,当表单递交后,通过javascript来禁用表单的递交按钮。
1 | <input type="checkbox" name="interest" value="football">足球 |
我们在模版里面增加了一个隐藏字段token,这个值我们通过MD5(时间戳)来获取唯一值,然后我们把这个值存储到服务器端(session控制,之后再说),以方便表单提交时比对判定。
1 | func login(w http.ResponseWriter, r *http.Request) { |
上面的代码输出到页面的源码如下:
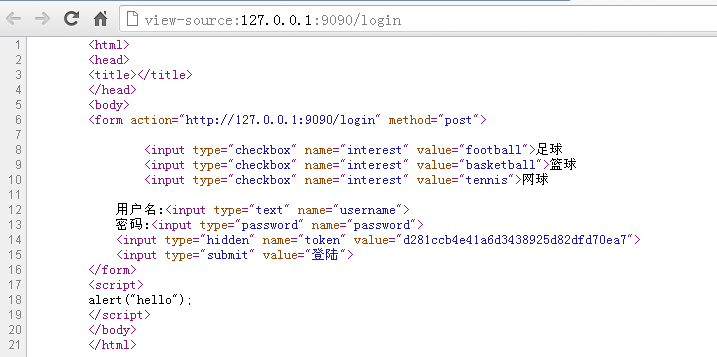
我们看到token已经有输出值,你可以不断的刷新,可以看到这个值在不断的变化。这样就保证了每次显示form表单的时候都是唯一的,用户递交的表单保持了唯一性。
我们的解决方案可以防止非恶意的攻击,并能使恶意用户暂时不知所措,然后,它却不能排除所有的欺骗性的动机,对此类情况还需要更复杂的工作。
处理文件上传
要使表单能够上传文件,首先第一步就是要添加form的enctype属性,enctype属性有如下三种情况:
1 | application/x-www-form-urlencoded 表示在发送前编码所有字符(默认) |
所以,创建新的表单html文件, 命名为upload.gtpl, html代码应该类似于:
1 | <html> |
在服务器端,我们增加一个handlerFunc:
1 | http.HandleFunc("/upload", upload) |
通过上面的代码可以看到,处理文件上传我们需要调用r.ParseMultipartForm,里面的参数表示maxMemory,调用ParseMultipartForm之后,上传的文件存储在maxMemory大小的内存里面,如果文件大小超过了maxMemory,那么剩下的部分将存储在系统的临时文件中。我们可以通过r.FormFile获取上面的文件句柄,然后实例中使用了io.Copy来存储文件。
获取其他非文件字段信息的时候就不需要调用
r.ParseForm,因为在需要的时候Go自动会去调用。而且ParseMultipartForm调用一次之后,后面再次调用不会再有效果。
通过上面的实例我们可以看到我们上传文件主要三步处理:
- 表单中增加enctype=”multipart/form-data”
- 服务端调用
r.ParseMultipartForm,把上传的文件存储在内存和临时文件中 - 使用
r.FormFile获取文件句柄,然后对文件进行存储等处理。
文件handler是multipart.FileHeader,里面存储了如下结构信息
1 | type FileHeader struct { |
我们通过上面的实例代码打印出来上传文件的信息如下

客户端上传文件
除了通过表单上传文件,然后在服务器端处理文件外,Go还支持模拟客户端表单功能支持文件上传:
1 | package main |
客户端通过multipart.Write把文件的文本流写入一个缓存中,然后调用http的Post方法把缓存传到服务器。
如果还有其他普通字段例如username之类的需要同时写入,那么可以调用multipart的WriteField方法写很多其他类似的字段。
访问数据库
database/sql接口
Go与PHP不同的地方是Go官方没有提供数据库驱动,而是为开发数据库驱动定义了一些标准接口,开发者可以根据定义的接口来开发相应的数据库驱动,这样做有一个好处,只要是按照标准接口开发的代码, 以后需要迁移数据库时,不需要任何修改。
以下为Go定义的标准接口:
sql.Register
这个存在于database/sql的函数是用来注册数据库驱动的,当第三方开发者开发数据库驱动时,都会实现init函数,在init里面会调用这个Register(name string, driver driver.Driver)完成本驱动的注册。
我们来看一下mymysql、sqlite3的驱动里面都是怎么调用的:
1 | //https://github.com/mattn/go-sqlite3驱动 |
我们看到第三方数据库驱动都是通过调用这个函数来注册自己的数据库驱动名称以及相应的driver实现。在database/sql内部通过一个map来存储用户定义的相应驱动。
1 | var drivers = make(map[string]driver.Driver) |
因此通过database/sql的注册函数可以同时注册多个数据库驱动,只要不重复。
在我们使用database/sql接口和第三方库的时候经常看到如下:
2
3
4
5
> "database/sql"
> _ "github.com/mattn/go-sqlite3"
> )
>
>
新手都会被这个
_所迷惑,其实这个就是Go设计的巧妙之处,我们在变量赋值的时候经常看到这个符号,它是用来忽略变量赋值的占位符,那么包引入用到这个符号也是相似的作用,这儿使用_的意思是引入后面的包名而不直接使用这个包中定义的函数,变量等资源。我们在流程和函数一节中介绍过init函数的初始化过程,包在引入的时候会自动调用包的init函数以完成对包的初始化。因此,我们引入上面的数据库驱动包之后会自动去调用init函数,然后在init函数里面注册这个数据库驱动,这样我们就可以在接下来的代码中直接使用这个数据库驱动了。
driver.Driver
Driver是一个数据库驱动的接口,他定义了一个method: Open(name string),这个方法返回一个数据库的Conn接口。
1 | type Driver interface { |
返回的Conn只能用来进行一次goroutine的操作,即不能把这个Conn应用于多个goroutine里面。
如下代码会出现错误
1 | ... |
上面这样的代码可能会使Go不知道某个操作究竟是由哪个goroutine发起的,从而导致数据混乱,比如可能会把goroutineA里面执行的查询操作的结果返回给goroutineB从而使B错误地把此结果当成自己执行的插入数据。
第三方驱动都会定义这个函数,它会解析name参数来获取相关数据库的连接信息,解析完成后,它将使用此信息来初始化一个Conn并返回它。
driver.Conn
Conn是一个数据库连接的接口定义,这个Conn只能应用在一个goroutine里面。
1 | type Conn interface { |
Prepare函数返回与当前连接相关的执行Sql语句的准备状态,可以进行查询、删除等操作。
Close函数关闭当前的连接,执行释放连接拥有的资源等清理工作。因为驱动实现了database/sql里面建议的conn pool,所以不用再去实现缓存conn之类的,这样会容易引起问题。
Begin函数返回一个代表事务处理的Tx,通过它你可以进行查询,更新等操作,或者对事务进行回滚、递交。
driver.Stmt
Stmt是一种准备好的状态,和Conn相关联,只能应用于一个goroutine中,不能应用于多个goroutine。
1 | type Stmt interface { |
Close函数关闭当前的链接状态,但是如果当前正在执行query,query还是有效返回rows数据。
NumInput函数返回当前预留参数的个数,当返回>=0时数据库驱动就会智能检查调用者的参数。当数据库驱动包不知道预留参数的时候,返回-1。
Exec函数执行Prepare准备好的sql,传入参数执行update/insert等操作,返回Result数据
Query函数执行Prepare准备好的sql,传入需要的参数执行select操作,返回Rows结果集
driver.Tx
事务处理一般就两个过程,递交或者回滚。数据库驱动里面也只需要实现这两个函数就可以
1 | type Tx interface { |
这两个函数一个用来递交一个事务,一个用来回滚事务。
driver.Execer
这是一个Conn可选择实现的接口
1 | type Execer interface { |
如果这个接口没有定义,那么在调用DB.Exec,就会首先调用Prepare返回Stmt,然后执行Stmt的Exec,然后关闭Stmt。
driver.Result
这个是执行Update/Insert等操作返回的结果接口定义
1 | type Result interface { |
LastInsertId函数返回由数据库执行插入操作得到的自增ID号。
RowsAffected函数返回query操作影响的数据条目数。
driver.Rows
Rows是执行查询返回的结果集接口定义
1 | type Rows interface { |
Columns函数返回查询数据库表的字段信息,这个返回的slice和sql查询的字段一一对应,而不是返回整个表的所有字段。
Close函数用来关闭Rows迭代器。
Next函数用来返回下一条数据,把数据赋值给dest。dest里面的元素必须是driver.Value的值除了string,返回的数据里面所有的string都必须要转换成[]byte。如果最后没数据了,Next函数最后返回io.EOF。
driver.RowsAffected
RowsAffected其实就是一个int64的别名,但是他实现了Result接口,用来底层实现Result的表示方式
1 | type RowsAffected int64 |
driver.Value
Value其实就是一个空接口,他可以容纳任何的数据
1 | type Value interface{} |
drive的Value是驱动必须能够操作的Value,Value要么是nil,要么是下面的任意一种
1 | int64 |
driver.ValueConverter
ValueConverter接口定义了如何把一个普通的值转化成driver.Value的接口
1 | type ValueConverter interface { |
在开发的数据库驱动包里面实现这个接口的函数在很多地方会使用到,这个ValueConverter有很多好处:
- 转化driver.value到数据库表相应的字段,例如int64的数据如何转化成数据库表uint16字段
- 把数据库查询结果转化成driver.Value值
- 在scan函数里面如何把driver.Value值转化成用户定义的值
driver.Valuer
Valuer接口定义了返回一个driver.Value的方式
1 | type Valuer interface { |
很多类型都实现了这个Value方法,用来自身与driver.Value的转化。
通过上面的讲解,你应该对于驱动的开发有了一个基本的了解,一个驱动只要实现了这些接口就能完成增删查改等基本操作了,剩下的就是与相应的数据库进行数据交互等细节问题了,在此不再赘述。
database/sql
database/sql在database/sql/driver提供的接口基础上定义了一些更高阶的方法,用以简化数据库操作,同时内部还建议性地实现一个conn pool。
1 | type DB struct { |
我们可以看到Open函数返回的是DB对象,里面有一个freeConn,它就是那个简易的连接池。它的实现相当简单或者说简陋,就是当执行Db.prepare的时候会defer db.putConn(ci, err),也就是把这个连接放入连接池,每次调用conn的时候会先判断freeConn的长度是否大于0,大于0说明有可以复用的conn,直接拿出来用就是了,如果不大于0,则创建一个conn,然后再返回之。
PostgreSQL
PostgreSQL 是一个自由的对象-关系数据库服务器(数据库管理系统),也是笔者在数据库课上学所学的数据库,所以就直接用它了。TIPS:打开pgAdmin如果出现无法连接并要求输入postgres密码的情况,请打开任务管理器>服务,找到并启动postgresql-x64-10即可
驱动
Go实现的支持PostgreSQL的驱动也很多,因为国外很多人在开发中使用了这个数据库。以下采用github.com/lib/pq驱动,它目前使用的人最多,在github上也比较活跃。
实例代码
数据库建表语句:
1 | CREATE TABLE userinfo |
看下面这个Go如何操作数据库表数据:增删改查
1 | package main |
PostgreSQL是通过$1,$2这种方式来指定要传递的参数,而不是MySQL中的?,另外在sql.Open中的dsn信息的格式也与MySQL的驱动中的dsn格式不一样,所以在使用时请注意它们的差异。还有pg不支持LastInsertId函数,因为PostgreSQL内部没有实现类似MySQL的自增ID返回,其他的代码几乎是一模一样。
mongoDB
MongoDB是一个高性能,开源,无模式的文档型数据库,是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,采用的是类似json的bjson格式来存储数据,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
目前Go支持mongoDB比较好的驱动有mgo,这个驱动非常的简明好用,但是作者弃坑了orz
官方推出了新的驱动mongo-driver,虽然繁琐一点,但支持了事务的处理,并且是官方的。
安装方面个人还是建议从github上clone下来然后本地go install go.mongodb.org/mongo-driver
这里吐槽一下,由于网络原因,不能够直接访问 golang.org,但我们还有镜像啊 Golang - Github
安装之后会有个warning,这不要紧,我们自己test一下以下的实例代码(当然请先打开mongo):
1 | package main |
连接后,获取test数据库中集合的句柄:
1 | collection := client.Database("test").Collection("trainers") |
一般需要保持连接到MongoDB的客户端,以便应用程序可以使用连接池,而不是为每个查询打开和关闭连接。
当然如果应用程序不再需要连接,也可以关闭连接client.Disconnect():
1 | err = client.Disconnect(context.TODO()) |
在Go中使用BSON对象
MongoDB中的JSON文档以称为BSON(二进制编码的JSON)的二进制表示形式存储。与其他将JSON数据存储为简单字符串和数字的数据库不同,BSON编码扩展了JSON表示形式,以包括其他类型,例如int,long,date,float point和decimal128。这使应用程序更容易可靠地处理,排序和比较数据。go驱动用两种类型来表示BSON数据,D和Raw,接下来我们主要使用D类型。
The D family consists of four types:
D: A BSON document, which is used in situations where order matters, such as MongoDB commands.M: An unordered map. It is the same asD, except it does not preserve order.A: A BSON array.E: A single element inside aD.
这是一个使用D类型构建的过滤器文档的示例,该类型可用于查找name字段与Alice或Bob匹配的文档:
1 | bson.D{{ |
CRUD操作
连接到数据库后,就该开始增删查改了:
插入文件
首先,创建一些新Trainer结构(就是个自定义的结构体)以插入数据库:
1 | ash := Trainer{"Ash", 10, "Pallet Town"} |
插入单个文档,用collection.InsertOne()方法:
1 | insertResult, err := collection.InsertOne(context.TODO(), ash) |
需要一次插入多个文档,collection.InsertMany()方法:
1 | trainers := []interface{}{misty, brock} |
更新文件
collection.UpdateOne()更新单个文档。它需要先匹配再更新,可以用以下bson.D类型构建:
1 | filter := bson.D{{"name", "Ash"}} |
然后,此代码将匹配名称为Ash的文档,并将Ash的age加1。
1 | updateResult, err := collection.UpdateOne(context.TODO(), filter, update) |
查找文件
查找单个文档,用collection.FindOne()。此方法返回单个结果,该结果可以解码为一个值。
用filter在更新查询中使用的相同变量来匹配名称为Ash的文档。
1 | // create a value into which the result can be decoded |
要查找多个文档,用collection.Find(),此方法返回一个游标Cursor。
Cursor提供了一系列文档,可以通过它们一次迭代和解码一个文档。一旦Cursor用尽,应该关闭Cursor。options程序包设置一些操作选项,比如设置一个限制,以便仅返回2个文档。
1 | // Pass these options to the Find method |
删除文件
用collection.DeleteOne()或collection.DeleteMany()删除文档。传参bson.D作为个过滤器,该参数将匹配集合中的所有文档。
1 | deleteResult, err := collection.DeleteMany(context.TODO(), bson.D{{}}) |
session和数据存储
session & cookie
当用户来到微博登陆页面,输入用户名和密码之后点击“登录”后浏览器将认证信息POST给远端的服务器,服务器执行验证逻辑,如果验证通过,则浏览器会跳转到登录用户的微博首页,在登录成功后,服务器如何验证我们对其他受限制页面的访问呢?因为HTTP协议是无状态的,所以很显然服务器不可能知道我们已经在上一次的HTTP请求中通过了验证。当然,最简单的解决方案就是所有的请求里面都带上用户名和密码,这样虽然可行,但大大加重了服务器的负担(对于每个request都需要到数据库验证),也大大降低了用户体验(每个页面都需要重新输入用户名密码,每个页面都带有登录表单)。既然直接在请求中带上用户名与密码不可行,那么就只有在服务器或客户端保存一些类似的可以代表身份的信息了,所以就有了cookie与session。
cookie,简而言之就是在本地计算机保存一些用户操作的历史信息(当然包括登录信息),并在用户再次访问该站点时浏览器通过HTTP协议将本地cookie内容发送给服务器,从而完成验证,或继续上一步操作。
session,简而言之就是在服务器上保存用户操作的历史信息。服务器使用session id来标识session,session id由服务器负责产生,保证随机性与唯一性,相当于一个随机密钥,避免在握手或传输中暴露用户真实密码。但该方式下,仍然需要将发送请求的客户端与session进行对应,所以可以借助cookie机制来获取客户端的标识(即session id),也可以通过GET方式将id提交给服务器。
cookie
Cookie是由浏览器维持的,存储在客户端的一小段文本信息,伴随着用户请求和页面在Web服务器和浏览器之间传递。用户每次访问站点时,Web应用程序都可以读取cookie包含的信息。浏览器设置里面有cookie隐私数据选项,打开它,可以看到很多已访问网站的cookies,如下图所示:
cookie是有时间限制的,根据生命期不同分成两种:会话cookie和持久cookie;
如果不设置过期时间,则表示这个cookie生命周期为从创建到浏览器关闭止,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览会话期的cookie被称为会话cookie。会话cookie一般不保存在硬盘上而是保存在内存里。
如果设置了过期时间(setMaxAge(606024)),浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie依然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存的cookie,不同的浏览器有不同的处理方式。
Go设置cookie
Go语言中通过net/http包中的SetCookie来设置:
1 | http.SetCookie(w ResponseWriter, cookie *Cookie) |
w表示需要写入的response,cookie是一个struct,让我们来看一下cookie对象是怎么样的
1 | type Cookie struct { |
我们来看一个例子,如何设置cookie
1 | expiration := time.Now() |
Go读取cookie
上面的例子演示了如何设置cookie数据,我们这里来演示一下如何读取cookie
1 | cookie, _ := r.Cookie("username") |
还有另外一种读取方式
1 | for _, cookie := range r.Cookies() { |
可以看到通过request获取cookie非常方便。
session
session,会话,其本来含义是指有始有终的一系列动作/消息,比如打电话是从拿起电话拨号到挂断电话这中间的一系列过程可以称之为一个session。然而当session一词与网络协议相关联时,它又往往隐含了“面向连接”和/或“保持状态”这样两个含义。
session在Web开发环境下的语义又有了新的扩展,它的含义是指一类用来在客户端与服务器端之间保持状态的解决方案。有时候Session也用来指这种解决方案的存储结构。
session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
但程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否包含了一个session标识-称为session id,如果已经包含一个session id则说明以前已经为此客户创建过session,服务器就按照session id把这个session检索出来使用(如果检索不到,可能会新建一个,这种情况可能出现在服务端已经删除了该用户对应的session对象,但用户人为地在请求的URL后面附加上一个JSESSION的参数)。如果客户请求不包含session id,则为此客户创建一个session并且同时生成一个与此session相关联的session id,这个session id将在本次响应中返回给客户端保存。
session机制本身并不复杂,然而其实现和配置上的灵活性却使得具体情况复杂多变。这也要求我们不能把仅仅某一次的经验或者某一个浏览器,服务器的经验当作普遍适用的。
对比
session和cookie目的相同,都是为了克服http协议无状态的缺陷,但完成的方法不同。session通过cookie,在客户端保存session id,而将用户的其他会话消息保存在服务端的session对象中,与此相对的,cookie需要将所有信息都保存在客户端。因此cookie存在着一定的安全隐患,例如本地cookie中保存的用户名密码被破译,或cookie被其他网站收集(例如:1. appA主动设置域B cookie,让域B cookie获取;2. XSS,在appA上通过javascript获取document.cookie,并传递给自己的appB)。
通过上面的一些简单介绍我们了解了cookie和session的一些基础知识,知道他们之间的联系和区别,做web开发之前,有必要将一些必要知识了解清楚,才不会在用到时捉襟见肘,或是在调bug时候如无头苍蝇乱转。接下来的几小节我们将详细介绍session相关的知识。
使用session
session创建过程
session的基本原理是由服务器为每个会话维护一份信息数据,客户端和服务端依靠一个全局唯一的标识来访问这份数据,以达到交互的目的。当用户访问Web应用时,服务端程序会随需要创建session,这个过程可以概括为三个步骤:
- 生成全局唯一标识符(sessionid);
- 开辟数据存储空间。一般会在内存中创建相应的数据结构,但这种情况下,系统一旦掉电,所有的会话数据就会丢失,如果是电子商务类网站,这将造成严重的后果。所以为了解决这类问题,你可以将会话数据写到文件里或存储在数据库中,当然这样会增加I/O开销,但是它可以实现某种程度的session持久化,也更有利于session的共享;
- 将session的全局唯一标示符发送给客户端。
以上三个步骤中,最关键的是如何发送这个session的唯一标识这一步上。考虑到HTTP协议的定义,数据无非可以放到请求行、头域或Body里,所以一般来说会有两种常用的方式:cookie和URL重写。
- Cookie 服务端通过设置Set-cookie头就可以将session的标识符传送到客户端,而客户端此后的每一次请求都会带上这个标识符,另外一般包含session信息的cookie会将失效时间设置为0(会话cookie),即浏览器进程有效时间。至于浏览器怎么处理这个0,每个浏览器都有自己的方案,但差别都不会太大(一般体现在新建浏览器窗口的时候);
- URL重写 所谓URL重写,就是在返回给用户的页面里的所有的URL后面追加session标识符,这样用户在收到响应之后,无论点击响应页面里的哪个链接或提交表单,都会自动带上session标识符,从而就实现了会话的保持。虽然这种做法比较麻烦,但是,如果客户端禁用了cookie的话,此种方案将会是首选。
Go实现session管理
通过上面session创建过程的讲解,读者应该对session有了一个大体的认识,但是具体到动态页面技术里面,又是怎么实现session的呢?下面我们将结合session的生命周期(lifecycle),来实现go语言版本的session管理。
session管理设计
我们知道session管理涉及到如下几个因素
- 全局session管理器
- 保证sessionid 的全局唯一性
- 为每个客户关联一个session
- session 的存储(可以存储到内存、文件、数据库等)
- session 过期处理
接下来我将讲解一下我关于session管理的整个设计思路以及相应的go代码示例:
Session管理器
定义一个全局的session管理器
1 | type Manager struct { |
Go实现整个的流程应该也是这样的,在main包中创建一个全局的session管理器
1 | var globalSessions *session.Manager |
我们知道session是保存在服务器端的数据,它可以以任何的方式存储,比如存储在内存、数据库或者文件中。因此我们抽象出一个Provider接口,用以表征session管理器底层存储结构。
1 | type Provider interface { |
- SessionInit函数实现Session的初始化,操作成功则返回此新的Session变量
- SessionRead函数返回sid所代表的Session变量,如果不存在,那么将以sid为参数调用SessionInit函数创建并返回一个新的Session变量
- SessionDestroy函数用来销毁sid对应的Session变量
- SessionGC根据maxLifeTime来删除过期的数据
那么Session接口需要实现什么样的功能呢?有过Web开发经验的读者知道,对Session的处理基本就 设置值、读取值、删除值以及获取当前sessionID这四个操作,所以我们的Session接口也就实现这四个操作。
1 | type Session interface { |
以上设计思路来源于database/sql/driver,先定义好接口,然后具体的存储session的结构实现相应的接口并注册后,相应功能这样就可以使用了,以下是用来随需注册存储session的结构的Register函数的实现。
1 | var provides = make(map[string]Provider) |
全局唯一的Session ID
Session ID是用来识别访问Web应用的每一个用户,因此必须保证它是全局唯一的(GUID),下面代码展示了如何满足这一需求:
1 | func (manager *Manager) sessionId() string { |
session创建
我们需要为每个来访用户分配或获取与他相关连的Session,以便后面根据Session信息来验证操作。SessionStart这个函数就是用来检测是否已经有某个Session与当前来访用户发生了关联,如果没有则创建之。
1 | func (manager *Manager) SessionStart(w http.ResponseWriter, r *http.Request) (session Session) { |
我们用前面login操作来演示session的运用:
1 | func login(w http.ResponseWriter, r *http.Request) { |
操作值:设置、读取和删除
SessionStart函数返回的是一个满足Session接口的变量,那么我们该如何用他来对session数据进行操作呢?
上面的例子中的代码session.Get("uid")已经展示了基本的读取数据的操作,现在我们再来看一下详细的操作:
1 | func count(w http.ResponseWriter, r *http.Request) { |
通过上面的例子可以看到,Session的操作和操作key/value数据库类似:Set、Get、Delete等操作
因为Session有过期的概念,所以我们定义了GC操作,当访问过期时间满足GC的触发条件后将会引起GC,但是当我们进行了任意一个session操作,都会对Session实体进行更新,都会触发对最后访问时间的修改,这样当GC的时候就不会误删除还在使用的Session实体。
session重置
我们知道,Web应用中有用户退出这个操作,那么当用户退出应用的时候,我们需要对该用户的session数据进行销毁操作,上面的代码已经演示了如何使用session重置操作,下面这个函数就是实现了这个功能:
1 | //Destroy sessionid |
session销毁
我们来看一下Session管理器如何来管理销毁,只要我们在Main启动的时候启动:
1 | func init() { |
我们可以看到GC充分利用了time包中的定时器功能,当超时maxLifeTime之后调用GC函数,这样就可以保证maxLifeTime时间内的session都是可用的,类似的方案也可以用于统计在线用户数之类的。
存储session
上一节我们介绍了Session管理器的实现原理,定义了存储session的接口,这小节我们将示例一个基于内存的session存储接口的实现,其他的存储方式,读者可以自行参考示例来实现,内存的实现请看下面的例子代码
1 | package memory |
上面这个代码实现了一个内存存储的session机制。通过init函数注册到session管理器中。这样就可以方便的调用了。我们如何来调用该引擎呢?请看下面的代码
1 | import ( |
当import的时候已经执行了memory函数里面的init函数,这样就已经注册到session管理器中,我们就可以使用了,通过如下方式就可以初始化一个session管理器:
1 | var globalSessions *session.Manager |
预防session劫持
session劫持是一种广泛存在的比较严重的安全威胁,在session技术中,客户端和服务端通过session的标识符来维护会话, 但这个标识符很容易就能被嗅探到,从而被其他人利用。它是中间人攻击的一种类型。
本节将通过一个实例来演示会话劫持,希望通过这个实例,能让读者更好地理解session的本质。
session劫持过程
我们写了如下的代码来展示一个count计数器:
1 | func count(w http.ResponseWriter, r *http.Request) { |
count.gtpl的代码如下所示:
1 | Hi. Now count:{{.}} |
然后我们在浏览器里面刷新可以看到如下内容:
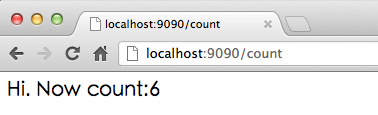
随着刷新,数字将不断增长,当数字显示为6的时候,打开浏览器(以chrome为例)的cookie管理器,可以看到类似如下的信息:
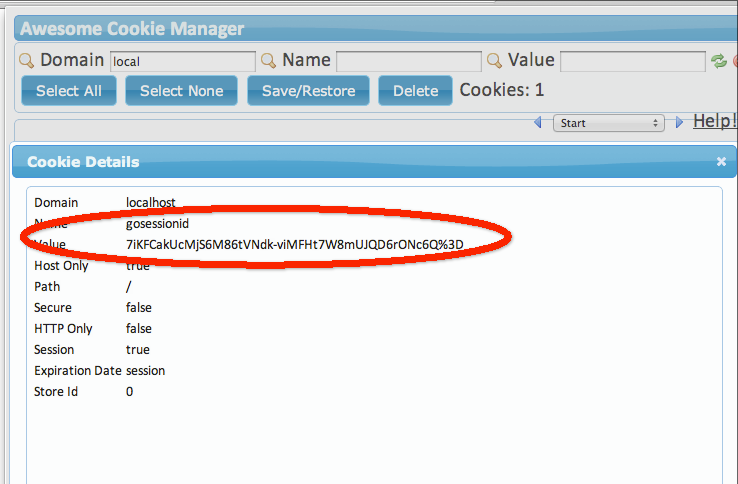
下面这个步骤最为关键: 打开另一个浏览器(这里我打开了firefox浏览器),复制chrome地址栏里的地址到新打开的浏览器的地址栏中。然后打开firefox的cookie模拟插件,新建一个cookie,把按上图中cookie内容原样在firefox中重建一份:
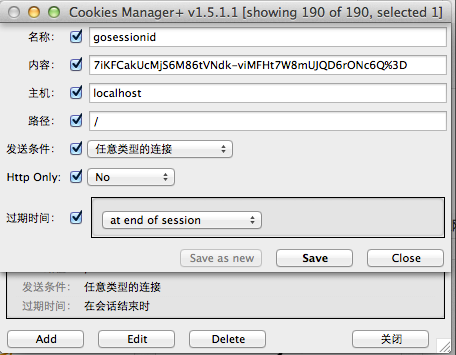
回车后,你将看到如下内容:
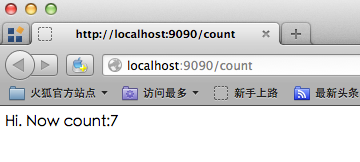
可以看到虽然换了浏览器,但是我们却获得了sessionID,然后模拟了cookie存储的过程。这个例子是在同一台计算机上做的,不过即使换用两台来做,其结果仍然一样。此时如果交替点击两个浏览器里的链接你会发现它们其实操纵的是同一个计数器。不必惊讶,此处firefox盗用了chrome和goserver之间的维持会话的钥匙,即gosessionid,这是一种类型的“会话劫持”。在goserver看来,它从http请求中得到了一个gosessionid,由于HTTP协议的无状态性,它无法得知这个gosessionid是从chrome那里“劫持”来的,它依然会去查找对应的session,并执行相关计算。与此同时 chrome也无法得知自己保持的会话已经被“劫持”。
session劫持防范
cookieonly和token
通过上面session劫持的简单演示可以了解到session一旦被其他人劫持,就非常危险,劫持者可以假装成被劫持者进行很多非法操作。那么如何有效的防止session劫持呢?
其中一个解决方案就是sessionID的值只允许cookie设置,而不是通过URL重置方式设置,同时设置cookie的httponly为true,这个属性是设置是否可通过客户端脚本访问这个设置的cookie,第一这个可以防止这个cookie被XSS读取从而引起session劫持,第二cookie设置不会像URL重置方式那么容易获取sessionID。
第二步就是在每个请求里面加上token,实现类似前面章节里面讲的防止form重复递交类似的功能,我们在每个请求里面加上一个隐藏的token,然后每次验证这个token,从而保证用户的请求都是唯一性。
1 | h := md5.New() |
间隔生成新的SID
还有一个解决方案就是,我们给session额外设置一个创建时间的值,一旦过了一定的时间,我们销毁这个sessionID,重新生成新的session,这样可以一定程度上防止session劫持的问题。
1 | createtime := sess.Get("createtime") |
session启动后,我们设置了一个值,用于记录生成sessionID的时间。通过判断每次请求是否过期(这里设置了60秒)定期生成新的ID,这样使得攻击者获取有效sessionID的机会大大降低。
上面两个手段的组合可以在实践中消除session劫持的风险,一方面, 由于sessionID频繁改变,使攻击者难有机会获取有效的sessionID;另一方面,因为sessionID只能在cookie中传递,然后设置了httponly,所以基于URL攻击的可能性为零,同时被XSS获取sessionID也不可能。最后,由于我们还设置了MaxAge=0,这样就相当于session cookie不会留在浏览器的历史记录里面。
RPC
RPC是远程过程调用Remote procedure call的简称,可以使运行远程代码就像本机代码一样而不用考虑通信编程以及开销。是分布式系统中不同节点间流行的通信方式,Go语言的标准库也提供了一个简单的RPC实现。
net/rpc
Package rpc provides access to the exported methods of an object across a network or other I/O connection. A server registers an object, making it visible as a service with the name of the type of the object. After registration, exported methods of the object will be accessible remotely. A server may register multiple objects (services) of different types but it is an error to register multiple objects of the same type.
Hello World
我们先构造一个HelloService类型,其中的Hello方法用于实现打印功能:
1 | type HelloService struct {} |
其中Hello方法必须满足Go语言的RPC规则:方法只能有两个可序列化的参数,其中第二个参数是指针类型,并且返回一个error类型,同时必须是公开的方法。
然后就可以将HelloService类型的对象注册为一个RPC服务,其中rpc.Register函数调用会将对象类型中所有满足RPC规则的对象方法注册为RPC函数,所有注册的方法会放在“HelloService”服务空间之下。然后我们建立一个唯一的TCP链接,并且通过rpc.ServeConn函数在该TCP链接上为对方提供RPC服务。
1 | func main() { |
下面是客户端请求HelloService服务的代码,首先是通过rpc.Dial拨号RPC服务,然后通过client.Call调用具体的RPC方法。在调用client.Call时,第一个参数是用点号链接的RPC服务名字和方法名字,第二和第三个参数分别我们定义RPC方法的两个参数。
1 | func main() { |
由这个例子可以看出RPC的使用其实非常简单。
Arith
这是go官网所给出的一个例子,A server wishes to export an object of type Arith:
1 | package server |
The server calls (for HTTP service):
1 | arith := new(Arith) |
At this point, clients can see a service “Arith” with methods “Arith.Multiply” and “Arith.Divide”. To invoke one, a client first dials the server:
1 | client, err := rpc.DialHTTP("tcp", serverAddress + ":1234") |
Then it can make a remote call:
1 | // Synchronous call |
or
1 | // Asynchronous call |
这里暂时只做简单介绍(毕竟只是为了写MIT6.824的Labs)更多详情可以见官方文档 https://golang.org/pkg/net/rpc/

