这里是一个关于os的lab,不怎么涉及到lab代码,而且现在lab已经更新很多版本了
Reference:做的时候参考了下网上的博客,这里给个link,写得挺好的。
lab1 机器启动
本实验作为ChCore 课程实验的第一个实验,分为三个部分:第一部分介绍ChCore 实验的基本知识,包括ARM 汇编语言与QEMU 模拟器的使用;第二部分熟悉ChCore 的引导加载程序(bootloader);第三部分需要对ChCore实现一些简单的内核态功能。
熟悉 ARM 汇编语言
AArch64 是ARMv8 ISA 的64 位执行状态。
ARM与Intel有诸多不同,最主要的区别是指令集。Intel是复杂指令集(CISC:Complex Instruction Set Computing)处理器,拥有功能更多更丰富的指令,允许对内存进行更复杂的操作。因此也拥有更多的指令操作,寻址模式,然而寄存器数量却比ARM少。CISC处理器主要应用在个人电脑,工作站,服务器当中。
ARM是精简指令集(RISC:Reduced Instruction set Computing)处理器,拥有更简单的指令集和更多的通用寄存器。同时ARM指令只操作寄存器,且只能使用Load/Stroe命令来读取和写入内存。即如果增加某个地址处的32位数据的值,你起码需要三个指令(取,加,存):首先将该地址处的数据加载到寄存器(取),然后增加寄存器里的值(加),最后再将寄存器里的值存储到原来的地址处(存)。
精简指令集单条指令执行更快,相应地也获得了更高的处理速度(减少单条指令的时钟周期)但更加要求注重软件书写效率。ARM有两种工作状态:ARM模式和Thumb模式(Thumb模式指令可以是2个字节或者4个字节)
ARM与x86其他区别:
- ARM中大部分指令都可以用作条件执行。
- x86和x86-64系列处理器使用小端(little-endian)地址格式。
- ARM在第三版以前是小端模式。之后变为大-小端(BI-endian)格式,允许大端或小端两种模式切换。
将汇编代码转换为机器码,当你编写完扩展名*.s的汇编源文件后,要用as编译然后用ld链接:
1 | $ as program.s -o program.o |
x19~x28:寄存器用于临时寄存器的保存
x29:帧指针寄存器,也叫做fp寄存器
sp: 栈指针寄存器,实际在AArch64架构下下同一函数中与x29寄存器值是一样的,注意这里跟x86-64架构对于栈帧回溯的方式是完全不一样的
x30:用于保存返回地址的寄存器,也叫做LR寄存器
QEMU与GDB
在实验中,由于需要在x86-64 平台上使用GDB 来调试AArch64 代码,因此使用gdb-multiarch代替了普通的gdb。QEMU可以启动一个GDB 远程目标(使用-s或-S参数启动),QEMU会在真正执行镜像中的指令前等待 GDB 客户端的连接。
打开两个终端,在chcore目录下,输入make qemu-gdb和make gdb命令可以分别打开带有 GDB 调试的 QEMU 以及 GDB,接下来使用 GDB 的where命令来跟踪入口(第一个函数)及 bootloader 的地址:
1 | 0x0000000000080000 in ?? () |
发现当前所在的函数为 _start(),而该函数在 boot/start.S 有定义:
1 | BEGIN_FUNC(_start) |
内核加载与引导
Raspi3 从闪存(SD 卡)中加载.img镜像中的bootloader 并执行。bootloader 的源文件由一个汇编文件boot/start.S和一个 C 文件boot/init_c.c组成。
boot-loader 包括两个功能:
- bootloader 通过函数arm64_elX_to_el1将处理器的异常级别从其他级别切换到EL1。
- bootloader 初始化引导UART,页表和MMU。然后,bootloader 跳转到实际的内核。
编译与可执行文件
在编译并链接诸如 ChCore 内核的可执行文件时,编译器会将每个 C 文件(.c)和汇编文件(.S)编译成为目标文件(objective file)(.o)。它是用二进制格式编码的机器指令编写的,但是由于文件内的符号地址等信息未完全生成,因此不能直接被运行。然后,链接器将所有已编译的目标文件链接(即在文件中填充其他文件中符号的地址等)成一个可执行目标文件,例如build/kernel.img,这个文件中是硬件可以运行的二进制机器指令组成的。可执行目标文件的常见格式是可执行和可链接格式(Executable and Linkable Format,ELF)二进制文件。
ELF 可执行文件以ELF 头部(ELF header)开始,后跟几个程序段(pro-gram section)。ELF 头部记录文件的结构,每个程序段都是一个连续的二进制块,(硬件或软件)加载器将它们作为代码或
数据加载到指定地址的内存中并开始执行以 build/kernel.img 文件为例,可以通过以下命令看到完整的ELF头部信息:
1 | os@ubuntu:~/Desktop/training/chcore-lab$ readelf -h build/kernel.img |
然后通过以下命令,我们可以看到 build/kernel.img 包含的程序段:
1 | os@ubuntu:~/Desktop/training/chcore-lab$ readelf -S build/kernel.img |
之前我们知道了第一条执行的指令地址为 0x0000000000080000,对比上面的结果发现正好是 init 段的地址。
.init:保存 bootloader 的代码和数据。这个特殊的段在CMakefiles.txt中定义。所有其余的程序段都是真正的 ChCore 内核。
然后之前的练习就给出了 build/kernel.image 的入口在 start.S 文件。
目前本实验中支持的内核是单核版本的内核,然而在 Raspi3 上电后,所有处理器会同时启动。lab需要我们结合 boot/start.S 中的启动代码来说明挂起其他处理器的控制流。所以这次我们来细看 boot/start.S 代码:
1 | #include <common/asm.h> |
先将mpidr_el1寄存器中的值读入x8中,同时只保留低8位,其他位置清空。
这样只有主处理器的mpidr_el1的低8位为0时才继续执行primary,其他的核的低8位不为0则继续执行进secondary_hang,而进入 secondary_hang 的线程会不断死循环来挂起。
MPIDR_EL1 provides an additional core identification mechanism for scheduling purposes in a cluster
MPIDR_EL1 末8位标识了多线程核中的单个线程,即只有第一个线程0x00可以继续执行primaryMRS(Move to Register from State register)指令类似MOV,把mpider_el1寄存器中的值读入x8中
CBZ 比较(Compare),如果结果为零(Zero)就转移(只能跳到后面的指令)
BL (branch with link) 当程序无条件跳转到link处执行,同时将当前PC值保存在R14中
ADR 是一条小范围的地址读取伪指令,它将基于PC的相对偏移的地址值读到目标寄存器中
进入primary的函数首先调用arm64_elX_to_el1将异常级别设为内核态,然后读入数组boot_cpu_stack地址,给栈分配了4096(0x1000)并设置栈指针寄存器,之后调用init_c函数完成切换到 EL1、初始化 UART、页表、MMU 的过程,最后通过 start_kernel 将控制权交给内核代码。
内核加载与执行
ELF 文件的加载(load)与执行(execute)是启动一个程序的两个重要的步骤:
- 加载是指将程序的 ELF 文件按照链接规则从存储器(如 ROM)上按照每个段的加载内存地址(Load Memory Address,LMA)拷贝到内存上指定的地址。
- 执行需要将ELF 文件中的段“放到”(可通过拷贝或页表映射等方式)虚拟内存地址(Virtual Memory Address,VMA),然后开始真正执行ELF文件中的代码。
通过objdump -h build/kernel.img也可以查看ELF 文件中每一个段的LMA 和VMA:
1 | os@ubuntu:~/Desktop/training/chcore-lab$ objdump -h build/kernel.img |
我们比较每一个段中的 VMA 和 LMA 可以发现,除了注释作用的 comment 段,就只有 init 段的 LMA 和 VMA 是相同的,而其他的 text rodata bbs 的 LMA 与 VMA 都有一个相同的偏移值 0xffffff000000000,于是我们打开链接脚本scripts/linker-aarch64.lds.in:
1 | #include "../boot/image.h" |
通过分析可知 init 段没有单独指定 VMA 和 LMA,所以这两个的地址都是 0x80000,而 text 段开始分别指定了 VMA 和 LMA,将 VMA 设置为了 KERNEL_VADDR + init_end, LMA 设置为 init_end,而KERNEL_VADDR 在 boot/image.h 被设置为 0xffffff000000000,由此 VMA 和 LMA 有了一定的偏移,后面的同理。
内核态基础功能
内核态输入输出
ChCore 中,内核态标准输出函数printk定义在kernel/common/printk.c中。其功能,和常用的libc 中的格式化标准输出printf()功能类似,不同的是,printf()是用户态可以调用的系统调用,其实现是需要调用的是内核态的格式化输出,而现在需要实现的正是内核态的格式化输出。下面补充一下打印不同进制数字的函数:
1 | static int printk_write_num(char **out, long long i, int base, int sign, |
函数栈
有了格式化标准输出后,我们可以增加更多用于调测的内核态功能,例如堆栈回溯:AArch64 的函数调用使用的是bl指令(类似于x86-64 中的call指令),并且使用栈结构保存函数调用信息:例如,函数的返回地址、所传入的参数等、上一个栈的指针等。因此,这些函数栈中的信息可以用来追踪函数的调用情况。
栈指针(Stack Pointer, SP)寄存器(AArch64 中使用sp寄存器)指向当前正在使用的栈顶(即栈上的最低位置)。栈的增长方向是内存地址从大到小的方向,弹出和压入是栈的两个基本操作。将值压入堆栈需要减少SP,然后将值写入SP 指向的位置。从堆栈中弹出一个值则是读取SP 指向的值,然后增加SP。
与之相反,帧指针(Frame Pointer,FP)寄存器(AArch64 中使用x29寄存器)指向当前正在使用的栈底(即栈上的最高位置)。FP 与 SP 之间的内存空间,即当前正在执行的函数的栈空间,用于保存临时变量等。在AArch64中,SP 和FP 都是64 位的地址,并且8 对齐(即保证可以被8整除)。
内核栈初始化(即初始化SP FP)的代码位于哪个函数?内核栈在内存中位于哪里?内核如何为栈保留空间?
内核栈的初始化操作,初始化在head.S汇编文件中,从中可以看到内核的栈顶为 kernel_stack 数组的起始地址+KERNEL_STACK_SIZE,因为kernel_stack是全局数组未初始化,因而位于.bss节,同时没有其他的全局未初始化变量了,因而实际的kernel_stack的起始内存地址就是.bbs节的vma地址,之前readelf来看其起始地址为ffffff0000090100,因而内核栈地址为ffffff0000090100 + 8192 = 0xffffff0000092100
1 | #include <common/asm.h> |
我们同时还可以通过qemu来调试验证是否正确,可以看到sp值确实是0xffffff0000092100,而FP则为0
1 | (gdb) break main |
在进入函数时,该函数在真正执行函数内部逻辑之前会有一些初始化栈帧指针的代码:通常通过将上一个函数所使用的 FP 压入栈来保存旧的 FP,然后再将当前的 SP 值复制到 FP 中。此外,这段初始化代码也会记录函数的返回地址、保存函数参数、保存寄存器的值等作用。返回地址保存在链接寄存器(Link Register,LR)(AArch64 中使用x30寄存器)中。根据这些调用惯例(calling convention),可以通过遵循已保存的 FP 指针链来追溯函数的调用顺序以及函数栈。这个特点可以用于调试,如定位代码的执行路径、查看调用函数时所用的参数等。
为了熟悉 AArch64 上的函数调用惯例,请在kernel/main.c中通过 GDB 找到stack_test函数的地址,在该处设置一个断点,并检查在内核启动后的每次调用情况。每个stack_test递归嵌套级别将多少个64位值压入堆栈,这些值是什么含义?我们可以首先在main.c里找到该函数的源码:
1 | // Test the stack backtrace function (lab 1 only) |
在ARM中栈指针SP寄存器为sp,帧指针FP寄存器为x29,而返回地址保存在链接寄存器LR即x30中,使用gdb:
1 | (gdb) break stack_test |
当调用stack_test时,SP首先将之前函数的返回地址LR压栈,再将之前的栈底FP压栈,然后压入函数的局部变量。
在AArch64 中,返回地址(保存在x30寄存器),帧指针(保存在x29寄存器)和参数由寄存器传递。但是,当调用者函数(caller function)调用被调用者函数(callee fcuntion)时,为了复用这些寄存器,这些寄存器中原来的值是如何被存在栈中的?
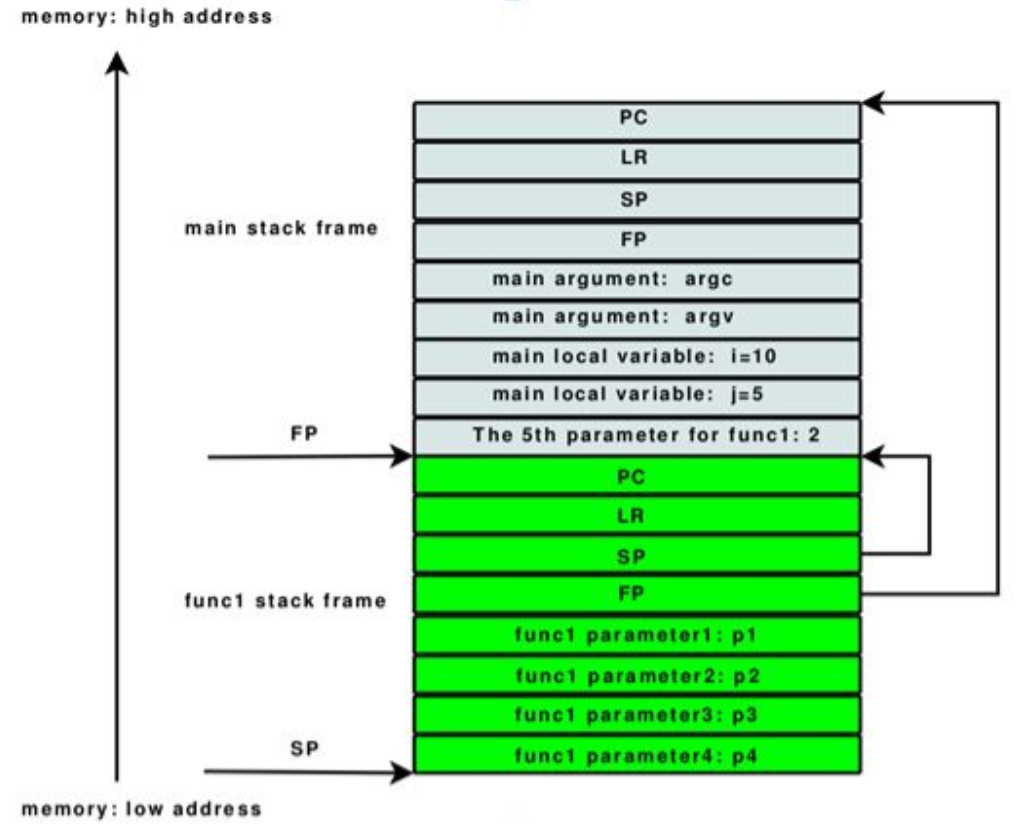
函数调用过程中涉及四个重要的寄存器:PC、LR、SP和FP。每个栈帧中的PC、LR、SP和FP都是寄存器的历史值,并非当前值。PC寄存器和LR寄存器均指向代码段, 其中PC代表代码当前执行到哪里了,LR代表当前函数返回后,要回到哪里去继续执行。SP和FP用来维护栈空间,其中SP指向栈顶,FP指向上一个栈帧的栈顶。
上图中蓝灰色部分是main函数的栈帧,绿色部分是func1的栈帧。左边的标有SP、FP的箭头分别指向func1的栈顶和main的栈顶。右边的两条折线代表函数func1返回的时候(栈收缩),SP和FP将要指向的地方。
由此,栈是通过FP和SP寄存器串成一串的,每个单元就是一个栈帧(也就是一个函数调用过程)。又由于LR是指向调用函数的(即PC寄存器的历史值,通过addr2line工具或者把可执行文件反汇编,可以看到func1中的LR落在main函数中,并且指向调用func1的下一条语句)如果能得到每个栈帧中的LR值,就能得到整个的函数调用链。
我们可以根据FP和SP寄存器回溯函数调用过程,以上图为例:函数func1的栈中保存了main函数的栈信息(绿色部分的SP和FP),通过这两个值,我们可以知道main函数的栈起始地址(也就是FP寄存器的值), 以及栈顶(也就是SP寄存器的值)。得到了main函数的栈帧,就很容易从里面提取LR寄存器的值了(FP向下偏移4个字节即为LR),也就知道了谁调用了main函数。以此类推,可以得到一个完整的函数调用链(一般回溯到 main函数或者线程入口函数就没必要继续了)。实际上,回溯过程中我们并不需要知道栈顶SP,只要FP就够了。
ChCore 通过调用stack_backtrace()函数进行栈回溯,该函数定义在kernel/monitor.c,并且回溯结果忽略该函数本身。该文件中的read_fp()函数可以通过内联汇编的方式,直接读到当前 FP 的值。stack_backtrace的输出格式如下:
Stack backtrace:
LR ffffff00000d009c FP ffffff000020f330 Args 0 0 ffffff000020f350 ffffff00000d009c 1
LR ffffff00000d009c FP ffffff000020f350 Args 1 3e ffffff000020f370 ffffff00000d009c 2
LR ffffff00000d009c FP ffffff000020f370 Args 2 3e ffffff000020f390 ffffff00000d009c 3
…
输出的第一行反映了调用stack_backtrace的函数,第二行反映了调用该函数的函数,依此类推,输出结果的每一行包含LR,FP 和Args,并且以十六进制表示。FP 表示函数栈的帧指针(x29),即刚进入该函数并设置FP 后的值。LR 表示函数返回后的指令地址,即调用者函数bl指令的下一条指令。bl [label] 指令跳转到label,并将寄存器x30设置为PC + 4。最后,在Args之后列出的五个值是所函数的前五个参数。如果函数的参数少于5 个,则多余的值是无效的。
例如,第一行是stack_test(0)的信息。在这一行中,LR 表示stack_test(0)返回之后的指令地址,FP 是该函数初始化栈之后的FP,而Args 为0(后面4个值无效)使用与示例相同的格式, 在kernel/monitor.c中 实现stack_backtrace:
FP+8处的值为当前函数LR,FP处的值为父函数的FP,FP的值就是当前函数的FP,FP-16处开始的值为当前函数的参数列表,一直递归到没有父函数时停止。
当前
read_fp得到的是stack_backtrace的 FP,而我们要求的函数是不包括stack_backtrace本身的,所以要来一层间接引用u64* fp = (u64*)(*(u64*)read_fp());取到这个 FP 的父函数的 FP。
1 | __attribute__ ((optimize("O1"))) |
最后可以看到结果:
1 | running ChCore: (0.8s) |
lab2 内存管理
物理内存管理
为了提高内存资源的利用率,ChCore 以4KB(PAGE_SIZE)为页的粒度对物理内存进行管理,同时采用了主流物理内存管理机制:伙伴系统(buddy system)
物理内存布局
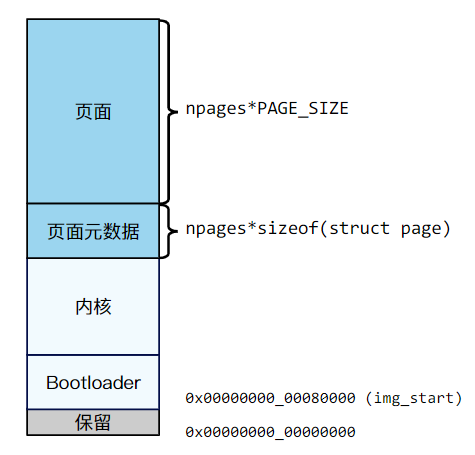
物理内存布局如图,其中物理地址img_start以下是保留的。
img_start~img_end(img_start被硬编码为 0x80000)被分为了两个区域:其中的底部区域作为 bootloader 代码、数据和 CPU 栈,每个 CPU 栈的大小为 4KB;顶部区域用于内核的代码、数据和 CPU 栈,每个CPU 栈的大小为 8KB。img_end以上空闲的物理内存由物理页分配器管理。分配器将内存区域划分为两个范围:元数据范围和页面范围,它们的大小与页面数(npages)有关。页面元数据包括 list_node 和 flags 等。
- 编译阶段:
- Bootloader的起始地址定义在链接脚本中,img_start 和 init_start 都被硬编码为了 0x80000,分别代表 chcore 镜像的开始地址和 bootloader 的开始地址。整个init 段存放的就是 Bootloader 的代码和全局变量,其结束地址就是 Bootloader 的结束地址。
- 内核部分包含的内容就是内核代码和全局变量,具体来说就是.text .data .rodata .bss. img_end就是整个内核区域的结束地址,至此链接脚本结束。
- 运行阶段:
- 页面元数据区和页面区的地址设定在/kernel/mm.c中的
mm_init()中实现,此时已经启用了MMU,操作的地址是虚拟地址。
- 页面元数据区和页面区的地址设定在/kernel/mm.c中的
伙伴系统
ChCore 基于以上的物理内存布局,实现物理内存分配器:每个物理页面对应一个struct page对象维护页面信息,并且通过该对象的链表跟踪哪些页面是空闲的。
伙伴系统中的每个内存块都有一个阶(order),阶是从0到指定上限buddy_max_order的整数。一个n阶的块的大小为 2n * PAGE_SIZE,因此这些内存块的大小正好是比它小一个阶的内存块的大小的两倍。
内存块的大小是2次幂对齐,使地址计算变得简单。当一个较大的内存块被分割时,被分成两个较小的内存块,这两个小内存块相互成为唯一的伙伴。一个分割内存块也只能与它唯一的伙伴块进行合并(合并成他们分割前的块)
struct global_mem是用来描述物理内存的数据结构,保存了伙伴系统中一组空闲内存块的链表free_lists,每组链表中使用list_head链接所有同order的内存块。
虚拟内存映射
AArch64 地址翻译
由于程序中的数据或指令的虚拟地址,无法直接被处理器用于访问物理内存,需要一套虚拟内存翻译为物理内存的机制。MMU 通过遍历内存中的页表,将程序中的虚拟地址翻译为物理地址。
内核与用户地址空间分离
为了保证进程间的隔离性,不同进程之间,以及用户态与内核态之间,所使用的页表是不同的,操作系统在进行上下文切换的时候会进行页表的切换。但是,大部分内存只由内核使用(在内核中保留了所有内存的映射,并且为了便于管理,内核往往固定了虚拟地址到物理地址的偏移),因此该部分的页表项很少需要更改。AArch64 体系构提供了几个特性来有效地处理该需求。
在ARM 中拥有两个页表的基地址寄存器:TTBR0_EL1 和TTBR1_EL1。这两个寄存器所翻译的虚拟地址范围可以通过TCR_EL1 进行配置。通常,操作系统会将TTBR1_EL1 寄存器用于存储内核映射的页表,将TTBR0_EL1 寄存器用于存储用户态程序的映射的页表。
AArch64 采用了两个页表基地址寄存器,相较于 x86-64 架构中只有一个页表基地址寄存器:
性能上,将用户态和内核态的寄存器分开,这样在像应用程序请求系统调用的过程里,就不需要再切换页表,也就省去了TLB刷新等操作。
安全上,系统进程与用户进程地址空间相互隔离,从地址转换的方面提升了安全性。
虚拟地址翻译与组成
对于 n 位物理地址空间中的虚拟地址(AArch64 支持的物理内存地址空间的大小为48 位),前 64-n 位[63:n] 必须全是0或1,否则地址将触发异常错误,MMU 使用剩余n位进行页表的遍历。
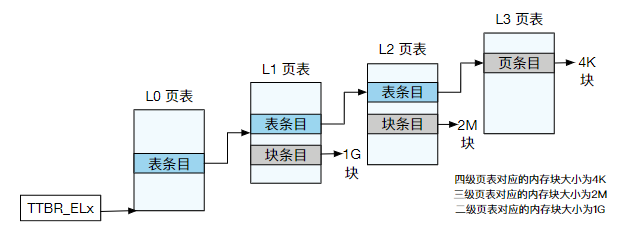
在四级页表中,虚拟地址大小为48 位,48 位地址对于每个页表级别有9 个比特位(即每一级页表有512 个条目)用于索引,最后的 12 位(页偏移)用于选择 4KB 内的一个字节。虚拟地址的[47:39] 位作为L0 页表的索引,L0 页表每个表条目的范围为512GB,并指向一个L1 表。在L1 表中也有512 个条目,[38:30] 位被用作索引来选择一个条目,每个条目都指向一个1GB 页或一个L2 表。[29:21] 位用于索引L2 表中的条目(512 个),每个条目指向一个2MB 页或一个L1 页表。在最后一级(L3)页表中,将[20:12] 位索引到有512 条目L3 表中,每个条目指向一个4KB 页。L3 页表中存储了物理页的页帧号(Page Frame Number,PFN),将PFN 和原本虚拟地址中的偏移量组合起来,就能够得到真正的物理地址。
ChCore 运行在支持虚拟内存 ARM 核心中,一旦 CPU 进入页模式(在bootloader/arch64/init/init_c.c中使能了该页表模式),就无法直接使用物理地址。所有内存引用被解释为虚拟地址,并由MMU 翻译,这意味着 C 代码的所有指针都是虚拟地址。然而 ChCore 内核经常需要将地址作为整数进行操作(例如指针加减),而不需要对指针进行解引用。例如在虚拟内存映射以及页表配置的时候,有时候需要使用虚拟地址,有时候需要使用物理地址。
为了更好地区分虚拟地址与物理地址,ChCore 源代码通过typedef区分了两种情况:vaddr_t表示虚拟地址,而paddr_t表示物理地址。这两种类型都是64 位整数(u64 ) 的别名,因此可以将其中一种类型转换为另一种类型而
不会报错。但是不论是paddr_t还是vaddr_t都不是指针的类型,因此不能够对这两个类型的变量做解引用。
这两个类型的区别是,将vaddr_t转换为指针类型后,可以通过解引用操作来读取该虚拟地址中的内容。然而,不能通过此方法读取paddr_t的内容。如果将paddr_t 强制转换为指针并取消引用它,硬件仍将其解释为虚拟地址,而非物理地址。因此访问的并不是该物理地址,而只是虚拟地址为这个值的内容。
内核地址空间
ChCore 将虚拟地址空间分为两部分:用户态地址空间与内核态地址空间。内核始终保持对高地址空间的完全控制,低地址用户态地址空间将在实验3 中实现。高地址与低地址的分界线由kernel/common/mmu.h中的KBASE宏定义。
为保证隔离性,ChCore 使用页表中的权限位来保证用户代码只访问用户态地址空间。否则可能会造成崩溃以及安全隐患,如用户数据覆盖内核数据、恶意的用户态进程修改内核数据等。用户态程序对内核态的任何内存都没有权限,而内核将能够读写这些内存。
在 AArch64 MMU 架构中,使用了两个 TTBR 寄存器,ChCore 使用一个 TTBR 寄存器映射内核地址空间,另一个寄存器映射用户态的地址空间,那么是否还需要通过设置页表位的属性来隔离内核态和用户态的地址空间? 应该还是需要,用户态程序可能会主动访问内核态虚拟地址,考虑安全问题,设置权限位还是必要的。
映射内核地址空间
ChCore 为什么要使用块条目组织内核内存? 哪些虚拟地址空间在 Boot 阶段必须映射,哪些虚拟地址空间可以在内核启动后延迟?
块2M比页4K大很多,可以在访问相同大小内存时使用较少的TLB,同时也能减少页表的级数,加快地址转换速度。内存模块要用的地址应该在 boot 阶段完成映射,进程模块、文件系统模块等在虚拟内存启动之后才启动的可以在内核启动后延迟。
为什么用户程序不能读写内核内存? 保护内核内存的具体机制是什么?
为了保证内核的安全,用户程序不能读写内核内存。用户程序访问内核内存的时候,会对程序状态寄存器里的标识位和页表项的标识位做合法性检查,非法的话会触发一个保护异常。
lab3 用户进程与异常处理
实现用户进程
在AArch64 中定义了四个异常级别,从低到高依次为EL0、EL1、EL2和EL3。ChCore仅使用了其中的两个异常级别:EL0 和EL1。其中,EL1 代表ChCore 中的内核模式,kernel/目录下的所有操作系统内核代码均运行于此异常级别。EL0代表用户模式,user/目录下的用户库函数代码与用户程序代码均以用户进程的抽象运行于此异常级别下。
基于Capability 的资源访问控制
在ChCore 中,公开给应用程序的所有内核资源均采用能力(Capability)机制进行管理。所有的内核资源(如物理内存等)均被抽象为了内核对象(kernel object),应用程序通过整型的标识符 Capability 访问从属于该进程的内核对象。为方便理解,可以类比Linux 中的文件描述符。在Linux 中,文件描述符(fd)即相当于一个整型的Capability,而文件本身则相当于一个内核对象。对于同一进程中的所有线程,其所能访问的内核对象以及Capability 与内核对象的映射关系完全相同。
Capability 把一个资源对象和访问权限封装到了一起,并对外提供一个整形 cap 做访问的句柄(句柄就是对资源对象的指针或者引用的一种抽象)
1 | // 仅为演示,删掉了部分异常处理的代码 |
线程与进程
ChCore 内核目前使用process结构体表示进程,使用thread结构体表示线程。ChCore 的一个进程是一些对特定内核对象享有相同的 Capability 的线程的集合。与Linux 一样,ChCore 中的每个进程可能包含多个线程,而每个线程则从属且仅从属于一个进程。
1 | struct process { |
slot_table:该进程有权访问的内核对象的数组(内核对象在数组中的索引即为该对象的cap)
node:从属于同一进程的线程的链表。
thread_ctx:该线程的上下文。目前,其中仅存储属于当前线程的所有寄存器的值和当前线程的类型,后续会向其中添加更多同调度相关的内容。
vmspace:该线程所创建的虚拟内存映射的相关信息
创建并执行主线程
由于目前ChCore 中尚无文件系统,所有二进制用户程序镜像将以静态链接的方式,被直接嵌入到内核镜像中,以便用户进程进行加载和运行。ChCore在 cpio 的帮助下将所有user/目录中编译出的 ELF 文件合并到了一个文件中,并将该文件通过变量binary_cpio_bin_start嵌入内核。
在 ChCore 中,创建一个初始进程并将正确的 ELF 文件载入到进程中开始执行的代码位于kernel/main.c的main()函数中。以下为从操作系统初始化到调用第一行用户代码为止的代码调用:
1 | main |
ChCore 启动后会依次初始化 uart 模块、内存管理模块、中断模块,而后调用 process_create_root 创建一个根进程,当前 Lab 中也只有这一个进程。其中,函数eret_to_thread最为核心,该函数使用 eret 指令,完成了从内核模式到用户模式的切换,并在用户模式下开始运行用户代码。
此外,一个用户线程在运行时,主要使用了以下内存区域:
- 用户栈:在thread_create_main中创建,是用户进程在用户模式运行时用作栈的一小段内存。
- 内核栈:在create_thread_ctx中创建,是用户进程在内核模式下运行时用作当前线程栈的一小段内存。struct thread_ctx即存储在当前线程的内核栈上。
- 代码/数据区域:在load_binary中创建,是用于存储从ELF 文件中加载出来的代码和数据段的一系列内存区域。
- 用户堆:由sys_handle_brk系统调用创建,是用作用户进程的堆的一小段内存。该部分内存的实际物理内存分配将在第一次访问时通过缺页异常处理完成。
thread_create_main会为进程创建一个主线程:首先初始化vmspace,然后将分配好的栈映射到虚拟地址空间里,之后载入ELF文件并将环境变量存入栈中,初始化线程并把线程挂载到进程上,刷新cache并返回cap号。
1 | int thread_create_main(struct process *process, u64 stack_base, |
create_thread_ctx创建 context 即申请一块内存。初始化 context 就是指定 SP_EL0、ELR_EL1、SPSR_EL1。
ELR 和 SPSR 成对存在,ELR记录从当前特权级返回到之前特权级时的返回地址,这里为程序入口函数的地址。SPSR记录程序的各种状态,这里只需更改特权级标志位, 因为要跳到用户态,相应的低四位全设为 0 就行,可以用宏 SPSR_EL1_USER 。设置好后用 eret 指令就会根据当前特权级的 ELR 和 SPSR 自动跳到另一个异常级别。
- Set SP_EL0 to stack.
- Set ELR_EL1 to the entrypoint of this thread.
- Set SPSR_EL1 to SPSR_EL1_EL0t as the properly PSTATE. One of the most
至于为什么SP是用户态,ELR和SPSR是内核态,这个在lab手册中有提到,创建并执行主线程的最后一部eret_to_thread最为核心。该函数使用eret 指令,完成了从内核模式到用户模式的切换,并在用户模式下开始运行用户代码。eret指令的语义主要包括:
- 检查当前异常级别的 SPSR 寄存器(在本例中为 SPSR_EL1)中的值,以选择在eret指令执行完成后处理器应处于的目标异常级别(在本例中为EL0)。
- 将当前异常级别SPSR 寄存器中的值设置到 PSTATE 相关的一系列寄存器中。
- 将当前异常级别 ELR(异常返回地址指针寄存器,本例中为ELR_EL1)中的内容设置到PC 寄存器中。
- 切换到目标异常级别并开始执行。切换完成后,处理器将会切换为采用目标异常等级的 SP 寄存器(在本例中为 SP_EL0)作为栈寄存器进行执行。
load_binary函数解析 ELF 文件,并将其内容加载到新线程的用户内存空间中,这里需要先说一下ELF文件的program header:
1 | struct elf_program_header { |
可以发现,程序段在虚拟内存里的长度p_memsz 和 程序段在文件中的长度p_filesz 并不是同一个东西,一个长度为n的数组在内存中可能占n个单位大小,但是在文件中只需要记录数组的定义,等到内存中再将其展开。同时还要注意注释中提到的页对齐问题,实际分配内存时我们要将 p_memsz 转换成页对齐的 seg_map_sz,即如果开始位置向前取整页,结尾位置向后取整页(用kernel/common/macro.h下的ROUND_UP和ROUND_DOWN来做)确保seg_map_sz是页对齐的,用作pom_init()的size。
异常处理
AArch64 中的异常
在ARM 术语中,异常是指低特权级软件(如用户程序)请求高特权软件(例如内核中的异常处理程序)采取某些措施以确保程序平稳运行的系统事件,包含同步异常和异步异常:
- 同步异常:通过直接执行指令产生的异常,其异常返回地址处的指令同异常发生的原因存在关联。
- 异步异常:与正在执行的指令无关的异常。
同步异常的来源包括同步中止(synchronous abort)和异常生成指令。当直接执行一条指令时,若取指令或数据访问过程失败,则会产生同步中止。异常生成指令则是指可以主动生成异常的指令,此类指令(包括svc,hvc ,
smc)通常被用户用于主动制造异常以请求高特权级别软件提供服务(如系统调用)。
异步异常的来源包括普通中断 IRQ、快速中断 FIQ 和系统错误 SError。IRQ 和 FIQ 是由其他与处理器连接的硬件产生的中断,系统错误则包含多种可能的原因。chcore lab3主要涉及同步异常。
异常向量表
发生异常后,处理器需要找到与发生的异常相对应的异常处理程序代码并执行。在 AArch64 中,存储于内存之中的异常处理程序代码被叫做异常向量 exception vector,而所有的异常向量被存储在一张异常向量表 exception vector table 中。
AArch64 中的每个异常级别都有其自己独立的异常向量表,其虚拟地址由该异常级别下的异常向量基地址寄存器(VBAR_EL3,VBAR_EL2 和 VBAR_EL1)决定。每个异常向量表中包含 16 个条目,每个条目里存储着发生对应异常时所需执行的异常处理程序代码。发生异常时,使用异常向量表中的哪个条目,取决于以下因素:
- 异常类型,即该异常是SError,FIQ,IRQ、同步异常中的哪一个。
- 如果在相同异常级别上触发,则异常处理程序将要使用的栈指针会对选择的表项产生影响(例如,在 EL2 中触发异常时,异常处理程序会根据 SPSel 寄存器的值决定使用 EL0(SP_EL0)还是 EL2(SP_EL2)的栈指针,而这一选择同样决定了需要使用的异常向量条目)。
- 如果异常是在较低的异常级别上触发的,则低异常级别是处理器的执行状态(AArch64 或AArch32)会对选择的表项产生影响。
假设AArch64处理器正在用户线程中执行代码,并且遇到了一条指令集中未定义的指令。此时,处理器会发生未定义指令异常,并执行如下主要操作:
- 处理器将异常原因放入 ESR_EL1 中,并将返回地址(即未定义指令的地址)放入ELR_EL1 中。
- 处理器检查 VBAR_EL1 以获得 EL1 中使用的异常向量表的地址。由于当前异常是来自AArch64 模式中EL0 特权级的同步异常,因此处理器将选择条目VBAR_EL1+0x400。
- 处理器将特权级切换到 EL1。这一过程中,包含了如保存 PSTATE、使用SP_EL1 作为栈指针等内容,从而完成了从用户栈到内核栈的切换。
- 处理器执行VBAR_EL1+0x400 处的代码,在ChCore 中,这是一条跳转到异常处理程序的b指令。
本实验中,ChCore 内除系统调用外所有的同步异常均交由handle_entry_c函数进行处理。遇到异常时,硬件将根据ChCore 的配置执行对应的汇编代码,将异常类型和当前异常处理程序条目类型作为参数传递,并最终调用handler_entry_c 使用C代码处理异常。
系统调用和缺页异常
系统调用
系统调用异常是通过 SVC (SuperVisor Call) 指令触发的,使用该指令后 ESR 将被设为一个特殊值,然后按照正常的异常处理流程定位到 sync_el0_64 这个函数中。因为很多其他的异常都会走这个函数处理,所以此时要检查下是否是通过 SVC 指令触发的异常。是的话走一下 el0_syscall 函数,根据 x8 寄存器里记录的系统调用号跳转到 syscall_table 中对应的函数里。
1 | sync_el0_64: |
之前说了,用户栈在thread_create_main创建,内核栈在create_thread_ctx创建,代码/数据区域在load_binary创建,用户堆则是由sys_handle_brk系统调用创建,是用作用户进程的堆的一小段内存,该部分内存的实际物理内存分配将在第一次访问时通过缺页异常处理完成。接下来就来分析一下sys_handle_brk函数。
1 | struct vmspace { |
首先回顾一下vmspace,每个进程都有一个 vmspace 记录了它的地址空间、页表、堆。
vmspace->user_current_heap 记录了堆的起始地址。vmspace->heap_vmr->size 记录了堆的长度。vmspace->heap_vmr->pmo 则是堆关联的物理内存对象 PMO,PMO 内部可能是好多个内存块所组成的一个链表。
sys_handle_brk接收一个参数addr,如果addr为0则会初始化这个堆:
pmo_init(pmo, PMO_ANONYM, 0, 0);,PMO_ANONYM表示lazy allocationvmspace->heap_vmr = init_heap_vmr(vmspace, vmspace->user_current_heap, pmo)
如果addr比这个heap大,则会更新vmspace->heap_vmr和相关pmo的size,实际的物理内存分配会在第一次访问时候通过pagefault来完成,如果比heap小的话,直接return -EINVAL,目前lab不支持缩容操作。
缺页异常
当AArch64的处理器发生缺页异常时,它会将发生错误的虚拟地址存储于FAR_ELx 寄存器中,并异常处理流程。
1 |
在handle_entry_c(int type, u64 esr, u64 address)中如果GET_ESR_EL1_EC(esr)为上述两种,则进到do_page_fault(esr, address)函数。在do_page_fault(u64 esr, u64 fault_ins_addr)里,如果GET_ESR_EL1_FSC(esr)是DFSC_TRANS_FAULT_LX,则进到handle_trans_fault(struct vmspace *vmspace, vaddr_t fault_addr)函数,该函数在检查完pmo合法性后,会分配一个物理页并把页映射到缺页异常的地址处。(pmo的真实物理地址不一定是连续的,实际的chcore所有物理页的分配都会记录在基数树(radix tree)上,lab这里只是进行了简化)
1 | int handle_trans_fault(struct vmspace *vmspace, vaddr_t fault_addr) |
lab4 多核处理
多核支持
ChCore 运行的 CPU 核心数量将从 1 扩展为 PLAT_CPU_NUM(定义在kernel/common/machine.h中,代表可用CPU核心的数量)。要使用这些 CPU 核心,需要添加对多核的支持。此外,随着CPU 核心的增多,可能会遇到并发问题。因此,需要拿锁以防止出现多个CPU核心中运行的代码同时修改某一内核关键数据,造成数据竞争。
多核启动
所有 CPU 核心在开机时会被同时启动,在引导时则会被分为两种类型。一个指定的 CPU 核心会引导整个操作系统和初始化自身,被称为主 CPU(primary CPU)。其他的CPU 核心只初始化自身即可,被称为副CPU(backup CPU)。CPU 核心仅在系统引导时有所区分,在其他阶段,每个CPU 核心都是被相同对待的与之前的实验一样,CPU 核心执行位于boot/start.S中的_start。此时,只有主CPU 能够开始执行_start中全部的代码,副CPU 则被阻塞直到主CPU 显式地将激活它们为止。主 CPU 在第一次返回用户态之前会在kernel/main.c中执行main()函数,进行操作系统的初始化任务。之后,主 CPU 会执行一系列逻辑以激活各个副CPU。
在boot/start.S中,会把当前 cpuid 放在 X8 寄存器里,如果当前CPU是主CPU则正常初始化,主 CPU 在完成自己的初始化后调用 enable_smp_cores,在此设置 secondary_boot_flag[cpuid] = 1,让副 CPU 可以继续执行完成初始化。而如果当前 CPU 为副 CPU,则设置好栈后循环等待直到 secondary_boot_flag[cpuid] != 0,跳转到 secondary_init_c进行初始化。
为了保证并发安全,故要求副 CPU 有序的、逐个的初始化,每个副 CPU 初始化完应设置 cpu_status[cpuid] = cpu_run,只有在上个设置好后才可以设置下个副 CPU 的 secondary_boot_flag[cpuid]
大内核锁
在本实验中,我们使用最简单的并发控制方法,即内核中的全局共享锁(大内核锁)即可达成这一目的。
具体而言,在CPU 核心以内核态访问任何数据之前,它应该首先获得大内核锁。同理,CPU 核心应当在退出内核态之前释放大内核锁。大内核锁的获取与释放,保证了同时只存在一个CPU 核心执行内核代码、访问内核数据,因此不会产生竞争。
ChCore 使用lock_kernel()和unlock_kernel()两个接口对大内核锁进行封装。在本实验中,为了在CPU 核心进入内核态时拿锁、离开内核态时放锁,应该在以下6 个位置调用上述接口:
- kernel/main.c中的main():主CPU 在激活副CPU 之前需要首先获得了大内核锁。
- kernel/main.c中的secondary_start():在初始化完成之后且副CPU 返回用户态之前获取大内核锁。
- kernel/exception/exception_table.S中的el0_syscall:在跳转到syscall_table中相应的syscall条目之前获取大内核锁(该部分汇编代码已实现完成)。
- kernel/exception/exception.c中的handle_entry_c:在该异常处理函数的第一行获取大内核锁。因为在内核态下也可能会发生异常,所以如果异常是在内核中捕获的,则不应获取大内核锁。
- kernel/exception/irq.c中的handle_irq:在中断处理函数的第一行获取大内核锁。与handle_entry_c类似,如果是内核异常,则不应获取该锁。
- kernel/exception/exception_table.S中的exception_return:在第一行中释放大内核锁。由于所有情况下,内核态返回用户态都使用exception_return,因此这是唯一需要调用unlock_kernel()的位置。
调度
本部分将首先实现协作式调度,从而允许当前在CPU 核心上运行的线程退出时,CPU 核心能够切换到另一个线程继续执行。然后,将实现抢占式调度,使得内核可以在一定时间片后重新获得对CPU 核心的控制,而无需当前运行线程的配合。最后,将扩展调度器,允许线程被调度到所有 CPU 核心上。
协作式调度
在本部分中,将实现一个基本的调度器,该程序调度在同一 CPU 核心上运行的线程(kernel/sched/sched.h)
协作式调度需要线程主动使用 sys_yield() 将 CPU 控制权让位给其他线程,抢占式调度则是由内核给每个线程分配一定的 CPU 时间片,当线程的时间片用完后由内核强制的将 CPU 控制权移交给另一个线程。
时间片轮转
当前 Lab 中 ChCore 使用 Round Robin 时间片轮转调度策略。每个 CPU 都有自己的就绪队列,表示已经准备好的、可以调度的线程。另外每个 CPU 还有一个空闲进程 idle(kernel/sched/policy_rr.c : idle_threads)用于在没有线程就绪时上去顶位。如果不这样做那 CPU 发现没有能调度的线程时就会卡在内核态,而我们进入内核态时都是持有大内核锁的,这个 CPU 在内核态干等着不出来,其他 CPU 就拿不到大内核锁,无法进入内核态。
每个CPU 核心都有自己rr_ready_queue的列表,该列表存储CPU 核心的就绪线程。一个线程只能出现在一个 CPU 核心的rr_ready_queue中。当 CPU 核心调用rr_sched_enqueue()时,应将给定线程放入自己的rr_ready_queue中,并将线程的状态置为TS_READY。同样,当 CPU 核心调用rr_sched_dequeue()时,应该从自己的rr_ready_queue中取出给定线程,并将线程状态置为TS_INTER,代表了线程的中间状态。
一旦CPU 核心要发起调度,它只需要调用rr_sched(),首先检查当前是否正在运行某个线程。如果是,它将调用rr_sched_enqueue()将线程添加回rr_ready_queue,然后调用rr_choose_thread()来选择要调度的线程。
rr_choose_thread首先检查 CPU 核心的rr_ready_queue是否为空。如果为空,rr_choose_thread返回 CPU 核心自己的空闲线程。如果没有,它将选择rr_ready_queue的队首并调用rr_sched_dequeue()使该队首出队,然后返回该队首。idle_thread不应出现在rr_ready_queue中。因此,rr_sched_enqueue()和rr_sched_dequeue()都应对空闲线程进行特殊处理。
rr_sched_init为已经实现好的初始化函数,会将就绪队列rr_ready_queue和空闲线程idle_threads初始化。它只在kernel/main.c的main()中主 CPU 初始时被调用一次,并且主 CPU 负责初始化rr_ready_queue和idle_threads中的所有条目。
rr_sched_enqueue将线程插入就绪队列,并设置进程状态为就绪态,关联到当前 CPU 上。需注意合法性判断(指针为空、是否为 idle 线程、是否已经处于就绪态)。
rr_sched_dequeue出队列。弹出的线程状态被置为TS_INTER,依旧要注意合法性检测。
rr_sched_choose_thread负责从就绪队列中选择一个线程。就绪队列为空时就选择idle线程。
rr_sched为调度操作的核心函数。先将当前线程插入就绪队列,然后通过rr_sched_choose_thread取出下一个就绪的线程,然后用switch_to_thread将其设为运行态,并让当前线程指针指向它。
current_threads是一个数组,分别指向每个 CPU 核心上运行的线程。与 lab 3 不同,本实验中current_thread现在是一个表示current_threads[smp_get_cpu_id()]的宏,尽管其语义不会改变。ready_thread_queue包含调度器的就绪线程(等待被调度的线程)列表。sched_ops表示 ChCore 中的调度器。它存储指向不同调度操作的函数指针,以支持不同的调度策略。
线程切换
目前 ChCore 的线程切换过程步骤有:
当前线程主动(协作式调度)或被动(抢占式调度)的引发中断,陷入内核态,在中断程序入口处调用
exception_enter保存上下文。调用
sched函数,切换current_threaderet_to_thread(switch_context()),恢复current_thread的上下文到寄存器中。
1 | void sys_yield(void) |
抢占式调度
使用刚刚实现的协作式调度器,ChCore 能够在单个 CPU 核心内部调度线程。然而,若用户线程不想放弃对CPU 核心的占据,内核便只能让用户线程继续执行,而无法强制用户线程中止。因此,在这一部分中,本实验将实现抢占式调度,以帮助内核定期重新获得对CPU 核心的控制权。
时钟中断
为了支持内核抢占 CPU,我们需要启用时钟中断。每个一小段时间触发一个硬件定时器中断。
1 | void exception_init_per_cpu(void) |
在实际的操作系统中,如果每次时钟中断都会触发调度,会导致调度时间间隔过短、增加调度开销。对每个线程, 在kernel/sched/sched.h中 维 护一个sched_cont,这对应了每个线程的预算(budget)。当处理时钟中断时,将当前线程budget—,调度器应只能在某个线程预算等于零时才能调度该线程。
时钟中断发生时将沿着 handle_irq -> plat_handle_irq -> handle_timer_irq -> sched_handle_timer_irq -> rr_sched_handle_timer_irq 的顺序逐级调用,我们要在 rr_sched_handle_timer_irq 对 budget 做一下变更操作。
1 | static inline void rr_sched_refill_budget(struct thread *target, u32 budget) |
在时钟中断返回前也要检查下能不能进行调度。
1 | void handle_irq(int type) |
系统调用 sys_yield 是立刻进行切换,所以我们也要对 budget 做一下清零操作。
1 | void sys_yield(void) |
处理器亲和性
到目前为止,已经实现了一个基本完整的调度器。但是,ChCore 中的Round Robin 策略为每个 CPU 核心维护一个rr_ready_queue,并且无法在CPU 核心之间调度线程。
目前 ChCore 创建的线程与父线程都在同一个 CPU 上,没有办法分发到其他的 CPU 上。为了解决这一问题我们给每个线程引入一个亲和性 affinity 标识,亲和性使线程可以绑定到特定的 CPU 核心。创建线程时,还应指定线程的亲和性。当将线程插入就绪队列时,如果它的 affinity 为 NO_AFF,那就插到当前 CPU 的就绪队列里;否则插到 affinity 号 CPU 的就绪队列里。
1 | int rr_sched_enqueue(struct thread *thread) |
同时为了让用户态程序可以在运行时设置线程的亲和性,系统提供了sys_set_affinity和sys_get_affinity系统调用,用于设置或获取线程的亲和性。
1 | int sys_set_affinity(u64 thread_cap, s32 aff) |
spawn()
ChCore 现在能运行kernel/main.c的main()中创建的进程,但chcore还应允许用户态程序执行特定二进制文件。
当操作系统执行给定的可执行二进制文件时,它应创建一个负责执行文件的新进程。Linux 里使用 fork() 和 exec() 两个步骤来执行一个程序文件。 但还存在 spawn() 这个接口实现了前两者组合后的功能。在 Linux 下查阅 posix_spawn() 的 manpage 可知, spawn() 是为了在某些没有 MMU 的小型机上用来在一定范围内替代 fork() 的。
spawn() 接口
user/lib/spawn.c中的spawn(),它首先获取特定文件的ELF(可执行和可链接格式),并将 ELF 传递给spawn()的核心函数。在本部分中,将实现名为launch_process_with_pmos_caps()的函数,然后使spawn()可运行。首先,我们将介绍核心功能的接口。
1 | int launch_process_with_pmos_caps(struct user_elf *user_elf,//指定要执行的特定文件的ELF结构 |
基本工作流
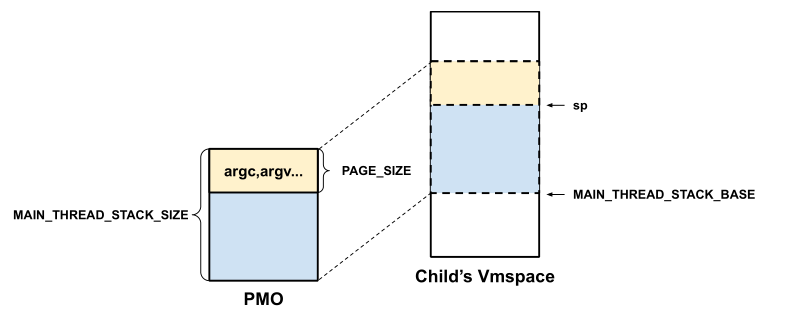
本节将实现一个基本的spawn()。父进程可以创建执行特定文件的子进程,但是父进程不能将任何信息传递给子进程,也不能从spawn()获取任何输出。
子进程的用户栈基地址为 MAIN_THREAD_STACK_BASE,大小为 MAIN_THREAD_STACK_SIZE(def.h)
用户栈顶部的一个 PAGE_SIZE 的空间用来存放用户程序的各种启动参数,程序开始运行时栈顶指针 SP 应该指向这个页的末尾处,即 MAIN_THREAD_STACK_BASE + MAIN_THREAD_STACK_SIZE - PAGE_SIZE
基本工作流程如下:
- 使用sys_create_process()创建一个子进程。
- 将二进制ELF 中的每个段映射到子进程。
- 使用sys_create_pmo()创 建 一 个 新 的 物 理 内 存 对 象 (PMO)main_stack_pmo, 用 于 子 进 程 的 堆 栈。PMO 的 大 小为MAIN_THREAD_STACK_SIZE,应被立即分配。
- 在父进程的本地内存中构造(准备)一个初始页面,该页面存储诸如argc,argv的参数。
- 使用sys_write_pmos()将初始页面写到main_stack_pmo的顶端页。
- 使用sys_write_pmo()将main_stack_pmo映射到子进程。应该将其映射到具有VM_READ和VM_WRITE权限的子进程的地址MAIN_THREAD_STACK_BASE。
- 创建子进程的主线程。当执行主线程时,它从sp开始其线程的栈。
为spawn() 支持传递pmo和cap
在本节中,将实现完整的spawn()。父进程能够将共享内存传递给子进程,并将给定的 capability 转移给子进程。实验中需要处理的参数是pmo_map_reqs,nr_pmo_map_reqs,caps和nr_caps。
在基本工作流程的第4 步之前,应该做以下几步:
- 检 查nr_pmo_map_reqs > 0, 然 后 用pmo_map_reqs调用sys_map_pmos()
- 检查nr_caps> 0,然后用caps调用usys_transfer_caps()
- 完成基本工作流程的步骤7之后,如果不为空,则设置child_process_cap和child_main_thread_cap
进程通信
尽管spawn()使父进程和子进程能够共享内存并相互通信。但是,如果两个进程没有父子关系,它们无法通过spawn()共享内存,进而相互通信。
ChCore 的进程间通信
ChCore 的IPC 接口不是传统的send()/recv()接口。其更像客户端-服务器模型,其中IPC 请求接收者是服务器,而IPC 请求发送者是客户端。
IPC实例

正常状态下进程间通信分为三步:
服务端调用
ipc_register_server()登记自己的消息处理函数,上图里该函数为ipc_dispatcher()客户端调用
ipc_register_client()登记自己的相关信息到指定的服务端上。客户端调用
ipc_call()向服务端发送信息,服务端在自己的消息处理函数里以函数参数的形式捕获到消息来进行后续的逻辑处理,最后使用ipc_return()返回处理的结果。
那客户端是如何标记自己要找的那个服务端的呢?下面引用一小段 ipc_data.c 中的代码:
1 | Copyret = spawn("/ipc_data_server.bin", &new_process_cap, &new_thread_cap, |
可以发现客户端是通过 spawn() 得到子进程的主线程的 cap,并以此来向该进程建立连接的。
IPC原理
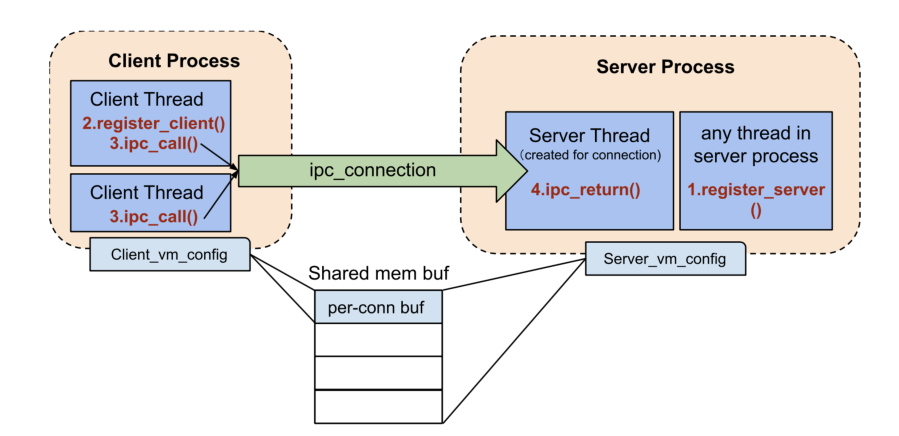
为了处理 IPC,服务器需要先注册回调函数ipc_dispatcher(),并且为了处理 IPC,其主线程不能够退出。ChCore 使用ipc/ipc.h中的ipc_connection将 客 户 端 与 服 务 器 一 一 绑 定。 对于每个ipc_connection,内核都会创建一个用户态服务器线程,负责执行服务器的ipc_dispatcher()。线程属于服务器的进程中,因此线程与服务器共享相同的vm_sapce。
为了发起 IPC 请求,客户端应首先创建到服务器的ipc_connection,然后才能将 IPC 请求发送到服务器。当内核处理sys_ipc_call()时,它将客户端线程的执行迁移到服务器线程(我们将此过程称为线程迁移)。然后内核返回到服务器线程以执行ipc_dispatcher()回调函数。服务器线程获取结果后,调用sys_ipc_return()。在处理sys_ipc_return()时,内核将服务器线程的执行再次迁移回客户端线程,进而完成整个IPC 的流程。
lab5 文件系统&shell
本实验将体现 ChCore 的微内核架构,实现一种基于索引节点(index node,inode)的内存文件系统:临时文件系统(temporary file system,tmpfs)、一个系统服务:用户态文件系统服务以及一个应用程序shell。本实验分为两个部分:在第一部分中,实现基于tmpfs 的用户态文件系统服务,ChCore 的文件系统服务能够提供一些文件的基本操作,如创建、删除、读写文件等。在第二部分中,实现shell 来与用户交互,需要实现一些基本命令,以及可以以 UNIX shell 为参照拓展其他功能。
文件系统
tmpfs
tmpfs 是基于 inode 的内存文件系统,即使用内存空间作为文件系统的存储空间,并将存储空间分为 inode 区域和数据区域。每个文件都有一个inode,该 inode 保存有关该文件的一些元数据,例如文件大小,以及该文件数据块的位置。数据区域存储文件数据块,tmpfs 中的文件数据块由一系列分散的内存页组成。文件分为常规文件和目录文件:常规文件存储数据本身,目录文件存储从文件名到目录项(dicrectory entry,dentry)的哈希表映射。
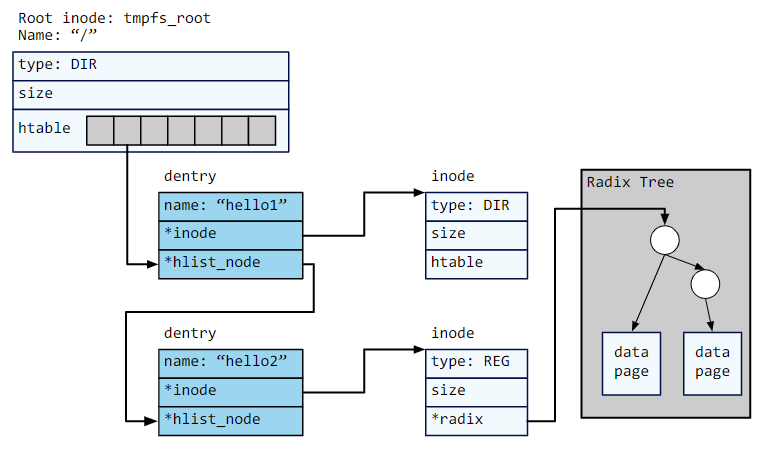
- inode:每个inode 对应一个文件,记录文件类型(type)(常规REG/目录DIR)和文件大小(size)。接口new_dir和new_reg用于创建这两种类型的inode。
- 目录:目录inode 存储一个指向哈希表htable的指针,该哈希表从文件名的哈希值映射到dentry。哈希表中的每个哈希桶都存储dentry 的链接表,并且通过hlist_node指针链接。其中,tmpfs_root表示根目录(/)的inode。
- 常规文件:常规文件的数据块以基数树的形式组织,树的根节点指针存在常规文件inode 中。该树的叶节点是大小为PAGE_SIZE的数据块(即内存页),通过内存页的顺序编号搜索。
1 | struct string { |
文件操作
实现基本文件操作前需要先实现一些修改文件结构的辅助函数:tfs_mknode和tfs_namex。tfs_mknode函数用于创建文件时,在父目录下创建目录 inode 或常规文件 inode。tfs_namex函数用于遍历文件系统结构以查找文件。
1 | static int tfs_mknod(struct inode *dir, const char *name, size_t len, int mkdir) |
文件读写是文件系统的基本功能,tmpfs 的读写操作是指内存中的数据读入或写到内存缓冲区。tfs_file_read和tfs_file_write两个函数分别用于以一定偏移量读取和写入一段长度的数据,并且返回实际的读写字节长度(读取不能超过文件大小)
1 | ssize_t tfs_file_write(struct inode * inode, off_t offset, const char *data, |
之前make user命令将用户态程序编译为 ELF文件(ramdisk/.bin或ramdisk/.srv),并用 cpio 将这些文件连接为一个后缀名为 cpio 的文件。cpio 的每个成员文件都包含一个头(在user/lib/cpio.h中定义),后面是文件内容。cpio 的末尾是一个名为TRAILER !!的空文件表示终止。在之前的实验中,我们将ramdisk.cpio的内容直接复制到没有文件结构的连续内存中。现在,tmpfs可以通过tfs_load_image加载ramdisk.cpio中的内容。
1 | int tfs_load_image(const char *start) |
文件系统服务
为了保证进程隔离,用户无法在文件系统服务中直接调用函数,因此用户程序通过 IPC 给文件系统服务发送请求的方式来使用文件系统。以文件读取为例,虚线上方是用户程序和文件系统的主要处理逻辑,虚线下方是文件系统服务的IPC 处理机制。用户程序通过调用由用户编写fs_read,使用ipc_call将消息发送到文件系统服务进程。
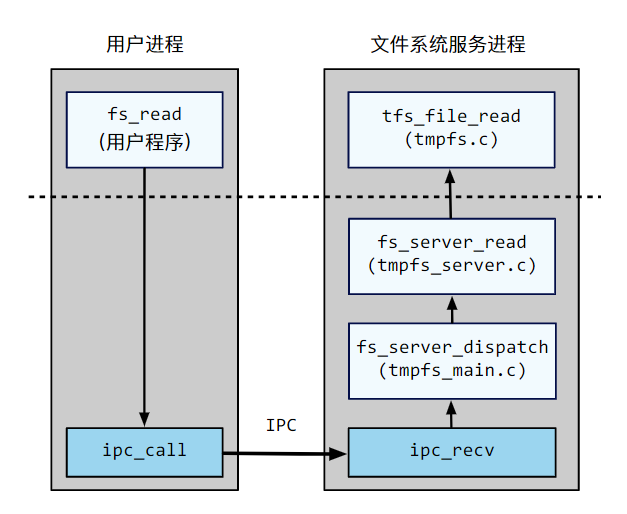
文件系统服务主函数在user/tmpfs/tmpfs_main.c中定义。其主要逻辑是轮询 IPC 请求,通过fs_dispatch将请求分派到适当的处理函数。在处理函数解析、处理后,通过 IPC 将结果发送回去。
处理函数在user/tmpfs/tmpfs_server.{h,c}中定义。在示例中,fs_dispatch将请求分派到fs_server_read,在解析请求后,调用tfs_file_read来实际执行读取的文件。
1 | static void fs_dispatch(ipc_msg_t * ipc_msg) |
1 | int fs_server_mkdir(const char *path) |

