翻看CSAPP的时候,发现本科教学cache讲得过于水了,就想直接再整理一篇相关的总结,以便之后翻看。
cache
早期计算机存储系统结构就是,CPU的寄存器、DRAM主存、磁盘,但由于CPU和主存之间的性能差距越来越大,不得已在两者间插入了个SRAM高速缓存存储器,即L1高速缓存(一级缓存)。最后cache存储结构就成了L1(4个时钟周期) - L2(10个时钟周期) - L3(50个时钟周期),L1一般为CPU专有,不在多个CPU中共享;L2 cache一般是多个CPU共享的,也可能装在主板上。L1 cache还可能分为instruction cache, data cache,这样CPU能同时取指令和数据。同时cache对于程序员是不可见的,完全是由硬件控制。
cache,高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
cache结构
假设内存容量为M,内存地址为m位:那么寻址范围为000…00~FFF…F(m位)
我们可以把内存地址分为以下三个区间:
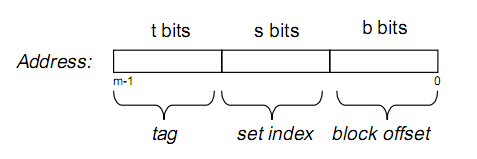
那么tag, set index, block offset三个区间有什么用呢?再来看Cache的逻辑结构:
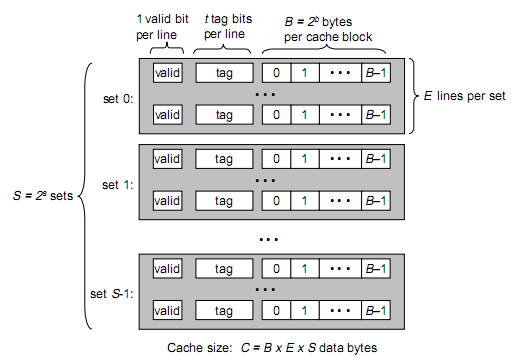
将两图做对比,可以得出:B = 2^b, S = 2^s
cache参数
一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中有B个存储单元(现代处理器中,这个存储单元一般是以字节(8 bits)为单位的,也是最小的寻址单元)因此在一个内存地址中,中间的s位决定了该单元被映射到哪一组,而最低的b位决定了该单元在cacheline中的偏移量。
valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,显然是无效的)
tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元。
当tag和valid校验成功时,称cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败时,就说明要访问的内存单元(也可能是连续的一些单元,如int占4个字节,double占8个字节)并不在cache中,这时就需要去内存中取了,这就是cache不命中的情况(cache miss)不命中发生时,系统会从内存中取得该单元,将其装入cache中,同时也放入CPU寄存器中,等待下一步处理。
从内存中取单元到cache时,会一次取一个cacheline大小的内存区域到cache中并存进相应的cacheline中。
例如:我们要取地址 (t, s, b) 内存单元,发生了cache miss,那么系统会取 (t, s, 00…000) 到 (t, s, FF…FFF)的内存单元,将其放入相应的cacheline中。
下面看看cache的映射机制:
当E=1时, 每组只有一个cacheline。那么相隔2^(s+b)个单元的2个内存单元,会被映射到同一个cacheline中(两个单元的索引位和偏移位相同)
当1<E<C/B时,每组有E个cacheline,不同的地址,只要中间s位相同,那么就会被映射到同一组中,同一组中被映射到哪个cacheline中是依赖于替换算法的。
当E=C/B,此时S=1,每个内存单元都能映射到任意的cacheline。带有这样cache的处理器几乎没有,因为这种映射机制需要昂贵复杂的硬件来支持。
不管哪种映射,只要发生了cache miss,那么必定会有一个cacheline大小的内存区域,被取到cache中相应的cacheline。

